Generalized Linear Models (GLM)
Grasp their theory and Scikit-Learn's implementation
Scikit-Learn version 0.23 introduced Generalized Linear Models (GLM), a capability I discovered through careful attention to release notes. Following publication of my book Hands-On Machine Learning with Scikit-learn and Scientific Python Toolkits, I monitor new algorithm implementations to document them as supplementary material.
The Generalized Linear Model extends traditional Linear Regression. Understanding GLMs requires examining what linear regressors actually predict.
What do Linear Regressors actually predict?
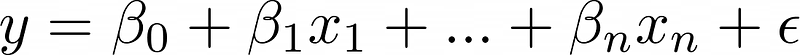
Machine learning relies on layers of abstraction. The fundamental linear regression equation includes an epsilon term representing normally distributed noise. However, the model's output is the expected value, not the actual target.
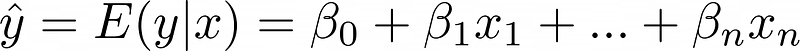
The predicted value represents the mean or expected value of y given x, expressed as E(y|x). With sufficient data points for each x value, multiple y values would exist, and the model predicts the expected value while expecting remaining targets to follow normal distribution.
Important Note: "For a given x, E(y|x) is constant. Therefore, when we say that the error is normally distributed with zero mean, we imply that the actual target, y, is also normally distributed, and its mean is E(y|x)."
Code Example:
from sklearn.linear_model import LinearRegression
x = [[1], [1], [2], [2]]
y = [9, 11, 19, 21]
m = LinearRegression()
m.fit(x, y)
m.predict([[1]]) # Returns 10
m.predict([[2]]) # Returns 20
For x=1, the predicted value equals 10, the mean of 9 and 11. For x=2, prediction is 20, the mean of 19 and 21.
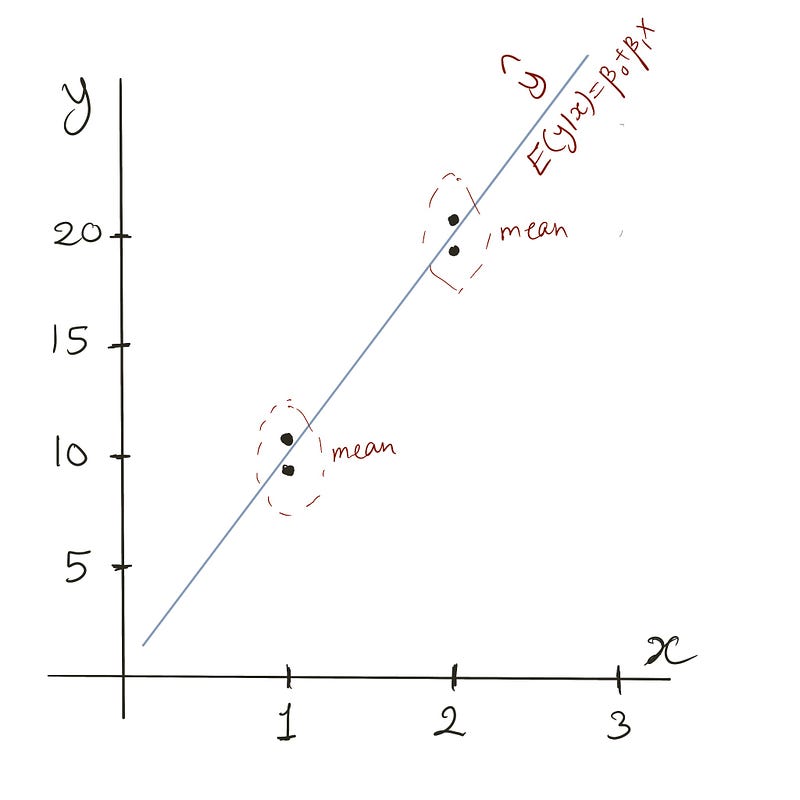
Additional Note: Models fitted by minimizing Mean Squared Error (MSE) produce means, while those minimizing Mean Absolute Error (MAE) produce medians.
Why Generalized Linear Models?
Linear models produce straight lines (or hyperplanes in multidimensional space), making them superior at extrapolation compared to algorithms like Gradient Boosting and Random Forest.
Extrapolation Example:
from sklearn.linear_model import LinearRegression
x = [[1], [2], [3]]
y = [10, 20, 30]
m = LinearRegression()
m.fit(x, y)
m.predict([[10]]) # Returns 100, as expected
Tree-based models fail at extrapolation:
from sklearn.ensemble import GradientBoostingRegressor
x = [[1], [2], [3]]
y = [10, 20, 30]
m = GradientBoostingRegressor()
m.fit(x, y)
m.predict([[10]]) # Returns 30!
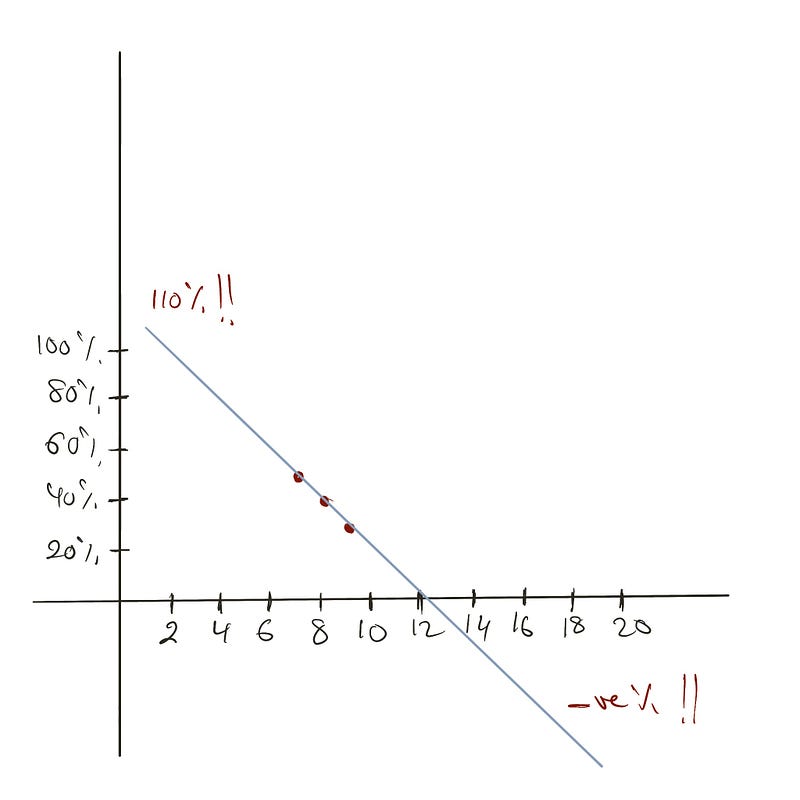
However, extrapolations can be problematic. Consider predicting item sales probability based on homepage position:
from sklearn.linear_model import LinearRegression
x = [[7], [8], [9]]
y = [0.50, 0.40, 0.30]
m = LinearRegression()
m.fit(x, y)
m.predict([[1], [20]]) # Returns 110% and -80%
Results are unrealistic—one position shows 110% probability while another shows negative probability. Since probabilities must fall between 0 and 1, solutions are needed.
Statisticians commonly use transformations. Rather than transforming inputs or outputs, GLMs transform the internal linear equation.
Believe me, you already know GLMs
The sigmoid function produces values between 0 and 1, matching probability constraints.
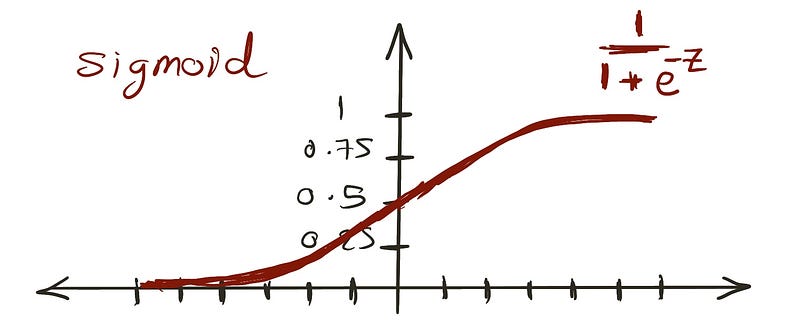
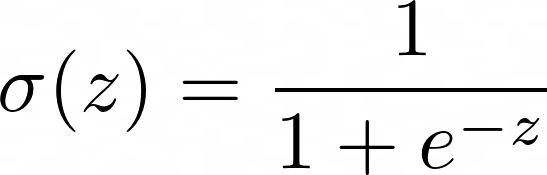
Substituting the linear equation for z ensures results remain between 0 and 1:
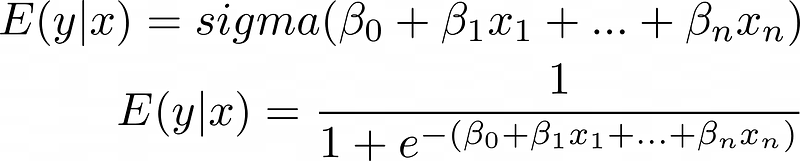
The transformation function is technically called the "inverse link function," though "link function" refers to its inverse—the logit or log odds:
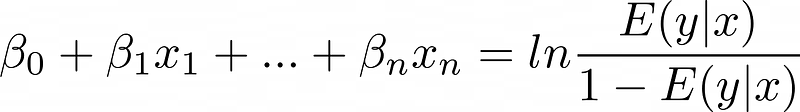
This model is logistic regression.
A common interview question asks whether Logistic Regression is classification or regression. Answers correlate with experience level rather than correctness.
Beyond the link function, error terms need not follow normal distribution. GLM key components include:
- A link function connecting E(y|x) to the linear equation
- Targets following exponential family distributions (normal distribution is one member)
The Poisson Regression
This regressor suits predicting counts: raindrops per square foot yearly, link clicks daily, or auction bids per item. While Poisson regression typically handles count predictions, other applications exist—the key is predicting non-negative integers.
Why is it good for counts?
The inverse link function in Poisson regression is exponential:
Regardless of input, exponential function outputs remain positive—appropriate for non-negative counts. The model equation becomes:
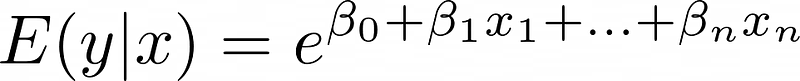
Normal distributions are symmetrical around their mean. If E(y|x) equals 2, actual targets could equally be 7 or -3, unacceptable for counts. Poisson regression requires skewed distribution instead.
Additionally, linear model errors maintain constant variance across all x values (homoscedasticity). A fortune estimated at $100 might acceptably be $104 or $92, but $100,000 represents intolerable error. Conversely, $10,000,000 fortunes tolerate variance in hundreds of thousands.
Poisson distribution satisfies requirements: it's skewed and its variance equals its mean, meaning variance grows linearly with E(y|x).
Code Implementation:
exp = lambda x: np.exp(x)[0]
x = np.array([[i] for i in np.random.choice(range(1,10), 100)])
y = np.array([exp(i) + np.random.normal(0,0.1*exp(i),1)[0] for i in x])
y[y<0] = 0
Then fit the Poisson model:
from sklearn.linear_model import PoissonRegressor
pr = PoissonRegressor(alpha=0, fit_intercept=False)
y_pred_pr = pr.fit(x, y).predict(x)
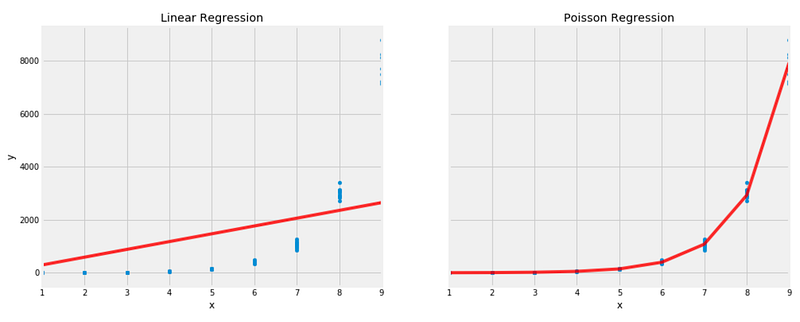
Poisson regression outperforms linear regression on this tailored dataset.
Conclusion
Generalized Linear Models extend ordinary least squares linear regression by incorporating link functions and assuming different target distributions from the exponential family.
Link functions constrain targets between 0 and 1 (logistic regression), above 0 (Poisson regression), or per specific constraints depending on the chosen link. Additional GLMs include Gamma and Inverse Gaussian models.
Scikit-Learn's GLM implementation supports regularization for cases with numerous predictors. Linear models excel at extrapolation but lack capacity to capture feature interactions or non-linearity—issues potentially addressed through future techniques.
Tarek Amr, September 21, 2021