النماذج الخطية المعممة (GLM)
افهم نظريتهم وتطبيق Scikit-Learn
إصدار Scikit-Learn 0.23 قدم النماذج الخطية المعممة (GLM)، قدرة اكتشفتها من خلال اهتمام دقيق بملاحظات الإصدار. بعد نشر كتابي Hands-On Machine Learning with Scikit-learn and Scientific Python Toolkits، بتابع تطبيقات الخوارزميات الجديدة عشان أوثقها كمواد تكميلية.
النموذج الخطي المعمم بيوسع الريجريشن الخطي التقليدي. فهم GLMs بيتطلب فحص إيه اللي المرتدات الخطية فعلاً بتتنبأ بيه.
إيه اللي المرتدات الخطية فعلاً بتتنبأ بيه؟
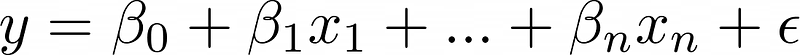
تعلم الآلة بيعتمد على طبقات من التجريد. معادلة الريجريشن الخطي الأساسية بتشمل حد إبسيلون بيمثل ضوضاء موزعة بشكل طبيعي. لكن، مخرجات النموذج هي القيمة المتوقعة، مش الهدف الفعلي.
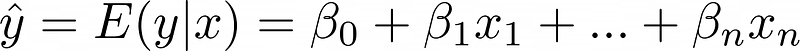
القيمة المتنبأ بها بتمثل المتوسط أو القيمة المتوقعة ل y معطى x، معبر عنها كـ E(y|x). مع نقاط بيانات كافية لكل قيمة x، قيم y متعددة هتكون موجودة، والنموذج بيتنبأ بالقيمة المتوقعة بينما بيتوقع إن الأهداف المتبقية تتبع التوزيع الطبيعي.
ملاحظة مهمة: "لـ x معطى، E(y|x) ثابت. لذلك، لما نقول إن الخطأ موزع بشكل طبيعي بمتوسط صفر، بنعني إن الهدف الفعلي، y، كمان موزع بشكل طبيعي، ومتوسطه هو E(y|x)."
مثال كود:
from sklearn.linear_model import LinearRegression
x = [[1], [1], [2], [2]]
y = [9, 11, 19, 21]
m = LinearRegression()
m.fit(x, y)
m.predict([[1]]) # بيرجع 10
m.predict([[2]]) # بيرجع 20
لـ x=1، القيمة المتنبأ بها بتساوي 10، متوسط 9 و 11. لـ x=2، التنبؤ هو 20، متوسط 19 و 21.
ملاحظة إضافية: النماذج المجهزة بتقليل متوسط الخطأ التربيعي (MSE) بتنتج متوسطات، بينما اللي بتقلل متوسط الخطأ المطلق (MAE) بتنتج وسطاء.
ليه النماذج الخطية المعممة؟
النماذج الخطية بتنتج خطوط مستقيمة (أو فراغات فائقة في الفضاء متعدد الأبعاد)، بتخليها متفوقة في الاستقراء مقارنة بالخوارزميات زي Gradient Boosting و Random Forest.
مثال استقراء:
from sklearn.linear_model import LinearRegression
x = [[1], [2], [3]]
y = [10, 20, 30]
m = LinearRegression()
m.fit(x, y)
m.predict([[10]]) # بيرجع 100، زي ما متوقع
النماذج المبنية على الأشجار بتفشل في الاستقراء:
from sklearn.ensemble import GradientBoostingRegressor
x = [[1], [2], [3]]
y = [10, 20, 30]
m = GradientBoostingRegressor()
m.fit(x, y)
m.predict([[10]]) # بيرجع 30!
لكن، الاستقراءات ممكن تكون مشكلة. خد في الاعتبار التنبؤ باحتمالية بيع منتج بناءً على موضعه في الصفحة الرئيسية:
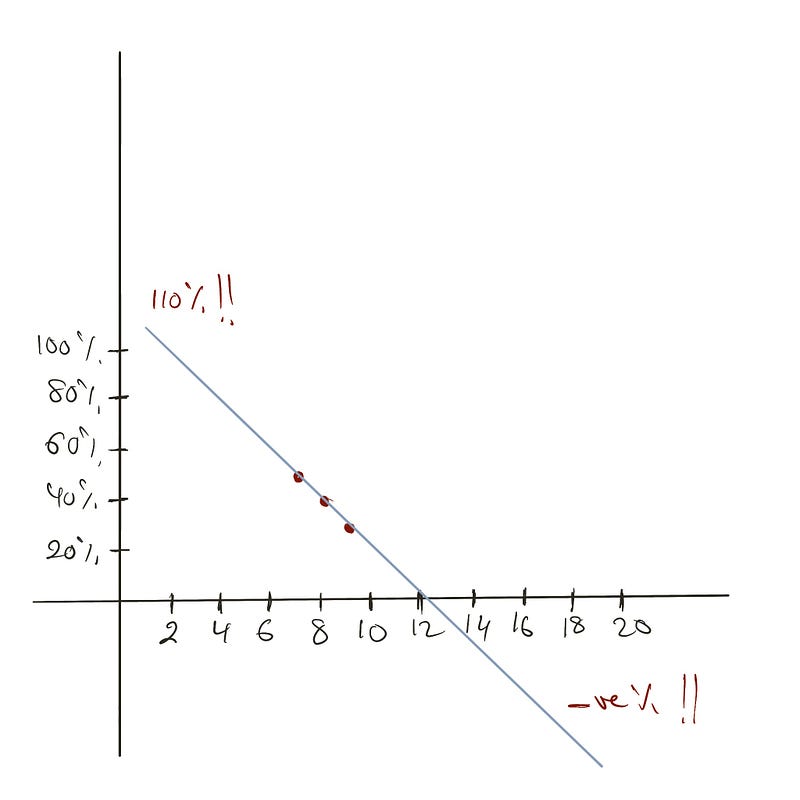
from sklearn.linear_model import LinearRegression
x = [[7], [8], [9]]
y = [0.50, 0.40, 0.30]
m = LinearRegression()
m.fit(x, y)
m.predict([[1], [20]]) # بيرجع 110% و -80%
النتائج مش واقعية—موضع بيوضح 110% احتمالية بينما التاني بيوضح احتمالية سالبة. بما إن الاحتمالات لازم تقع بين 0 و 1، حلول مطلوبة.
الإحصائيين عادةً بيستخدموا تحويلات. بدلاً من تحويل المدخلات أو المخرجات، GLMs بتحول المعادلة الخطية الداخلية.
صدقني، إنت عارف GLMs فعلاً
دالة السيجمويد بتنتج قيم بين 0 و 1، بتطابق قيود الاحتمالية.
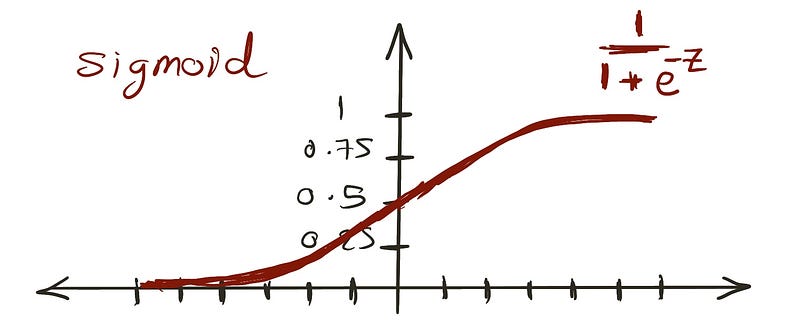
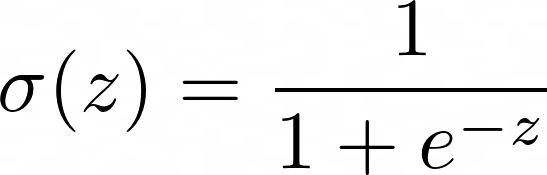
استبدال المعادلة الخطية لـ z بيضمن إن النتائج تفضل بين 0 و 1:
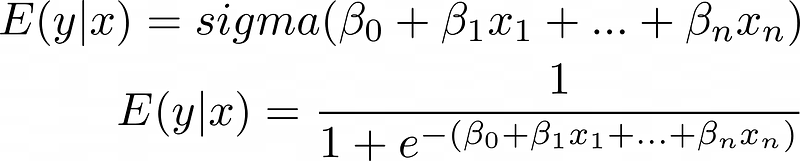
دالة التحويل تقنياً بنسميها "دالة الربط العكسية"، رغم إن "دالة الربط" بتشير لعكسها—اللوجيت أو log odds:
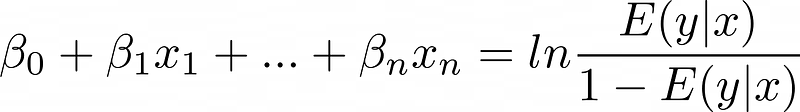
النموذج ده هو الريجريشن اللوجستي.
سؤال مقابلة شائع بيسأل لو الريجريشن اللوجستي تصنيف ولا ريجريشن. الإجابات بتترابط مع مستوى الخبرة بدلاً من الصحة.
بعيداً عن دالة الربط، حدود الخطأ مش لازم تتبع التوزيع الطبيعي. المكونات الأساسية لـ GLM بتشمل:
- دالة ربط بتوصل E(y|x) بالمعادلة الخطية
- أهداف بتتبع توزيعات العائلة الأسية (التوزيع الطبيعي عضو واحد)
ريجريشن بواسون
المرتد ده مناسب للتنبؤ بالعدات: قطرات المطر لكل قدم مربع سنوياً، نقرات الروابط يومياً، أو عروض المزاد لكل منتج. بينما ريجريشن بواسون عادةً بيتعامل مع تنبؤات العد، تطبيقات تانية موجودة—المفتاح هو التنبؤ بأرقام صحيحة غير سالبة.
ليه كويس للعدات؟
دالة الربط العكسية في ريجريشن بواسون أسية:
بغض النظر عن المدخل، مخرجات الدالة الأسية بتفضل موجبة—مناسبة للعدات غير السالبة. معادلة النموذج بتبقى:
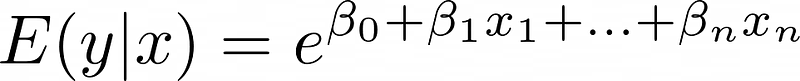
التوزيعات الطبيعية متماثلة حول متوسطها. لو E(y|x) بيساوي 2، الأهداف الفعلية ممكن تكون 7 أو -3 بالتساوي، غير مقبول للعدات. ريجريشن بواسون بيتطلب توزيع منحرف بدلاً من كده.
بالإضافة، أخطاء النموذج الخطي بتحافظ على تباين ثابت عبر كل قيم x (التجانس). ثروة مقدرة بـ 100 دولار ممكن تبقى 104 أو 92 دولار بشكل مقبول، بس 100,000 دولار بتمثل خطأ لا يطاق. بالعكس، ثروات 10,000,000 دولار بتتحمل تباين في مئات الآلاف.
توزيع بواسون بيحقق المتطلبات: هو منحرف وتباينه بيساوي متوسطه، يعني التباين بينمو خطياً مع E(y|x).
تطبيق الكود:
exp = lambda x: np.exp(x)[0]
x = np.array([[i] for i in np.random.choice(range(1,10), 100)])
y = np.array([exp(i) + np.random.normal(0,0.1*exp(i),1)[0] for i in x])
y[y<0] = 0
بعدين جهز نموذج بواسون:
from sklearn.linear_model import PoissonRegressor
pr = PoissonRegressor(alpha=0, fit_intercept=False)
y_pred_pr = pr.fit(x, y).predict(x)
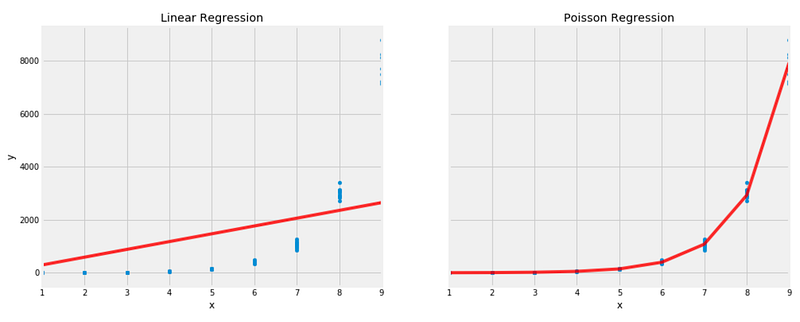
ريجريشن بواسون بيتفوق على الريجريشن الخطي على مجموعة البيانات المصممة دي.
الخلاصة
النماذج الخطية المعممة بتوسع ريجريشن المربعات الصغرى العادي بدمج دوال الربط وافتراض توزيعات مختلفة للهدف من العائلة الأسية.
دوال الربط بتقيد الأهداف بين 0 و 1 (الريجريشن اللوجستي)، فوق 0 (ريجريشن بواسون)، أو حسب قيود محددة اعتماداً على الربط المختار. GLMs إضافية بتشمل نماذج جاما وجاوسيان العكسية.
تطبيق Scikit-Learn لـ GLM بيدعم التنظيم للحالات مع متنبئات عديدة. النماذج الخطية متميزة في الاستقراء بس ناقصها القدرة على التقاط تفاعلات الخصائص أو اللاخطية—مشاكل ممكن تتعالج من خلال تقنيات مستقبلية.
طارق عمرو، 21 سبتمبر 2021