Gegeneraliseerde Lineaire Modellen (GLM)
Begrijp hun theorie en Scikit-Learn's implementatie
Scikit-Learn versie 0.23 introduceerde Gegeneraliseerde Lineaire Modellen (GLM), een mogelijkheid die ik ontdekte door zorgvuldige aandacht aan release notes. Na publicatie van mijn boek Hands-On Machine Learning met Scikit-learn en Scientific Python Toolkits, monitor ik nieuwe algoritme-implementaties om ze te documenteren als aanvullend materiaal.
Het Gegeneraliseerd Lineair Model breidt traditionele Lineaire Regressie uit. Het begrijpen van GLM's vereist onderzoek naar wat lineaire regressors eigenlijk voorspellen.
Wat voorspellen Lineaire Regressors eigenlijk?
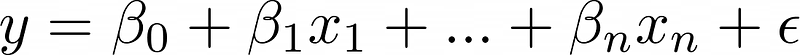
Machine learning vertrouwt op lagen van abstractie. De fundamentele lineaire regressievergelijking bevat een epsilon-term die normaal verdeelde ruis vertegenwoordigt. De output van het model is echter de verwachte waarde, niet het werkelijke doel.
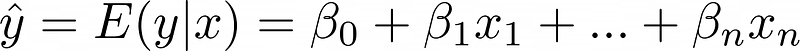
De voorspelde waarde vertegenwoordigt het gemiddelde of de verwachte waarde van y gegeven x, uitgedrukt als E(y|x). Met voldoende datapunten voor elke x-waarde zouden meerdere y-waarden bestaan, en het model voorspelt de verwachte waarde terwijl het verwacht dat resterende doelen een normale verdeling volgen.
Belangrijke Opmerking: "Voor een gegeven x is E(y|x) constant. Daarom, wanneer we zeggen dat de fout normaal verdeeld is met nul gemiddelde, impliceren we dat het werkelijke doel, y, ook normaal verdeeld is, en het gemiddelde ervan is E(y|x)."
Code Voorbeeld:
from sklearn.linear_model import LinearRegression
x = [[1], [1], [2], [2]]
y = [9, 11, 19, 21]
m = LinearRegression()
m.fit(x, y)
m.predict([[1]]) # Retourneert 10
m.predict([[2]]) # Retourneert 20
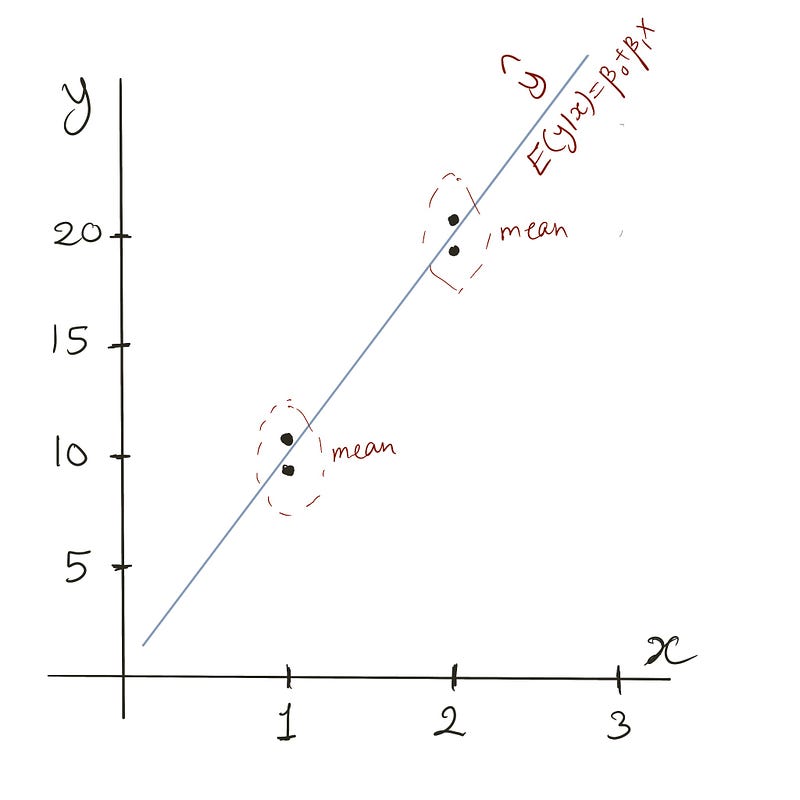
Voor x=1 is de voorspelde waarde gelijk aan 10, het gemiddelde van 9 en 11. Voor x=2 is de voorspelling 20, het gemiddelde van 19 en 21.
Aanvullende Opmerking: Modellen die zijn gefit door Mean Squared Error (MSE) te minimaliseren produceren gemiddelden, terwijl die die Mean Absolute Error (MAE) minimaliseren medianen produceren.
Waarom Gegeneraliseerde Lineaire Modellen?
Lineaire modellen produceren rechte lijnen (of hypervlakken in multidimensionale ruimte), waardoor ze superieur zijn in extrapolatie vergeleken met algoritmen zoals Gradient Boosting en Random Forest.
Extrapolatie Voorbeeld:
from sklearn.linear_model import LinearRegression
x = [[1], [2], [3]]
y = [10, 20, 30]
m = LinearRegression()
m.fit(x, y)
m.predict([[10]]) # Retourneert 100, zoals verwacht
Op bomen gebaseerde modellen falen bij extrapolatie:
from sklearn.ensemble import GradientBoostingRegressor
x = [[1], [2], [3]]
y = [10, 20, 30]
m = GradientBoostingRegressor()
m.fit(x, y)
m.predict([[10]]) # Retourneert 30!
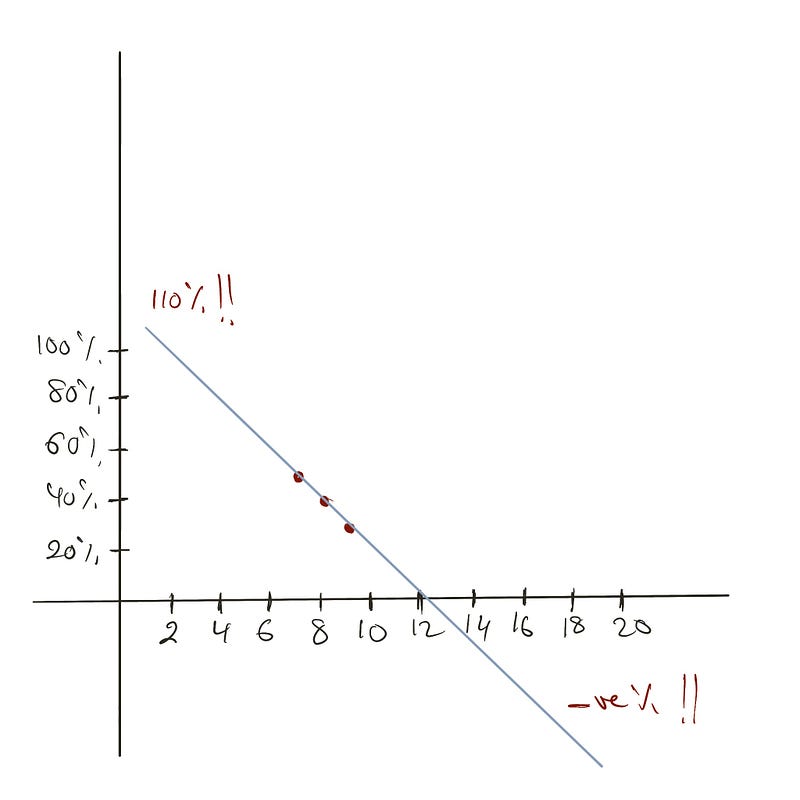
Extrapolaties kunnen echter problematisch zijn. Overweeg het voorspellen van de verkoopkans van artikelen op basis van de positie op de homepage:
from sklearn.linear_model import LinearRegression
x = [[7], [8], [9]]
y = [0.50, 0.40, 0.30]
m = LinearRegression()
m.fit(x, y)
m.predict([[1], [20]]) # Retourneert 110% en -80%
Resultaten zijn onrealistisch—één positie toont 110% kans terwijl een andere negatieve kans toont. Aangezien kansen tussen 0 en 1 moeten vallen, zijn oplossingen nodig.
Statistici gebruiken vaak transformaties. In plaats van inputs of outputs te transformeren, transformeren GLM's de interne lineaire vergelijking.
Geloof me, je kent GLM's al
De sigmoid-functie produceert waarden tussen 0 en 1, die overeenkomen met kansbeperkingen.
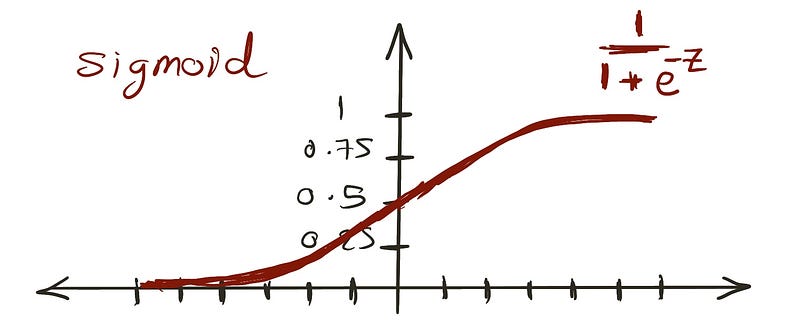
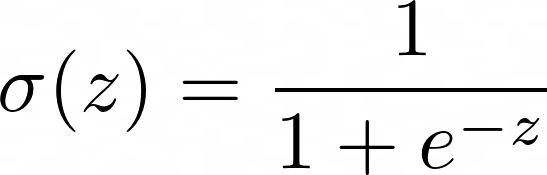
Het vervangen van de lineaire vergelijking voor z zorgt ervoor dat resultaten tussen 0 en 1 blijven:
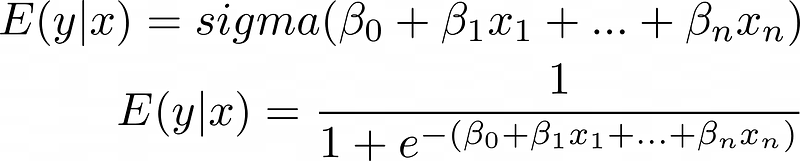
De transformatiefunctie wordt technisch de "inverse linkfunctie" genoemd, hoewel "linkfunctie" verwijst naar zijn inverse—de logit of log odds:
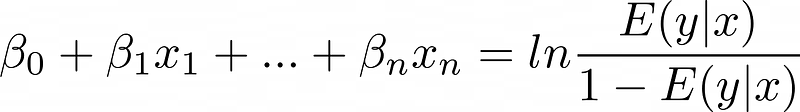
Dit model is logistische regressie.
Een veel voorkomende interviewvraag is of Logistische Regressie classificatie of regressie is. Antwoorden correleren met ervaringsniveau in plaats van juistheid.
Naast de linkfunctie hoeven fouttermen niet een normale verdeling te volgen. GLM sleutelcomponenten omvatten:
- Een linkfunctie die E(y|x) verbindt met de lineaire vergelijking
- Doelen die exponentiële familie verdelingen volgen (normale verdeling is één lid)
De Poisson Regressie
Deze regressor is geschikt voor het voorspellen van tellingen: regendruppels per vierkante voet per jaar, linkklikken dagelijks, of veilingbiedingen per artikel. Hoewel Poisson-regressie typisch tellingvoorspellingen behandelt, bestaan andere toepassingen—de sleutel is het voorspellen van niet-negatieve gehele getallen.
Waarom is het goed voor tellingen?
De inverse linkfunctie in Poisson-regressie is exponentieel:
Ongeacht de invoer blijven exponentiële functie-outputs positief—geschikt voor niet-negatieve tellingen. De modelvergelijking wordt:
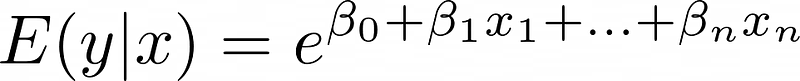
Normale verdelingen zijn symmetrisch rond hun gemiddelde. Als E(y|x) gelijk is aan 2, kunnen werkelijke doelen evengoed 7 of -3 zijn, onaanvaardbaar voor tellingen. Poisson-regressie vereist in plaats daarvan een scheve verdeling.
Bovendien behouden lineaire modelfouten constante variantie over alle x-waarden (homoscedasticiteit). Een fortuin geschat op $100 kan acceptabel $104 of $92 zijn, maar $100.000 vertegenwoordigt een ondraaglijke fout. Omgekeerd tolereren fortuinen van $10.000.000 variantie in honderdduizenden.
Poisson-verdeling voldoet aan de vereisten: het is scheef en zijn variantie is gelijk aan zijn gemiddelde, wat betekent dat variantie lineair groeit met E(y|x).
Code Implementatie:
exp = lambda x: np.exp(x)[0]
x = np.array([[i] for i in np.random.choice(range(1,10), 100)])
y = np.array([exp(i) + np.random.normal(0,0.1*exp(i),1)[0] for i in x])
y[y<0] = 0
Fit vervolgens het Poisson-model:
from sklearn.linear_model import PoissonRegressor
pr = PoissonRegressor(alpha=0, fit_intercept=False)
y_pred_pr = pr.fit(x, y).predict(x)
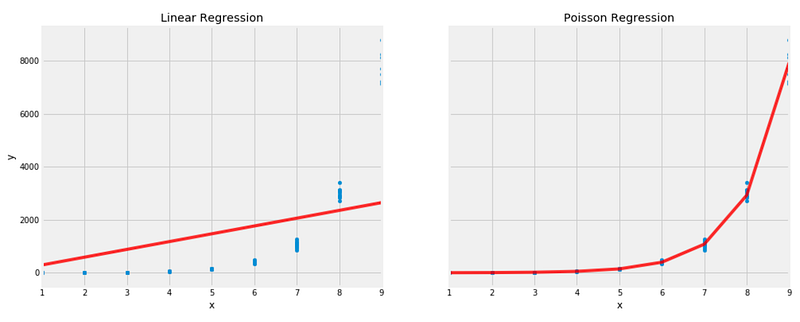
Poisson-regressie presteert beter dan lineaire regressie op deze op maat gemaakte dataset.
Conclusie
Gegeneraliseerde Lineaire Modellen breiden gewone kleinste kwadraten lineaire regressie uit door linkfuncties op te nemen en verschillende doelverdelingen van de exponentiële familie aan te nemen.
Linkfuncties beperken doelen tussen 0 en 1 (logistische regressie), boven 0 (Poisson-regressie), of per specifieke beperkingen afhankelijk van de gekozen link. Aanvullende GLM's omvatten Gamma- en Inverse Gaussische modellen.
Scikit-Learn's GLM-implementatie ondersteunt regularisatie voor gevallen met talrijke voorspellers. Lineaire modellen blinken uit in extrapolatie maar missen capaciteit om feature-interacties of niet-lineariteit vast te leggen—problemen die mogelijk worden aangepakt door toekomstige technieken.
Tarek Amr, 21 september 2021