Een Zachte Introductie tot Betrouwbaarheidsintervallen
Veel sollicitanten missen begrip van fundamentele statistische concepten. In zakelijke contexten verzamelen dataprofessionals informatie, berekenen samenvattende statistieken en communiceren bevindingen aan besluitvormers.
Ben Je Zelfverzekerd Genoeg in Je Samenvatting?
Een kritieke vraag komt naar voren: na het berekenen van een gemiddelde uit 500 sessies die 10 minuten gebruikersbetrokkenheid tonen, hoe zeker kun je zijn? Mogelijke zorgen zijn onder andere:
- Niet-representatieve steekproef bij toeval
- Temporele variaties (weekenden vs. doordeweekse dagen, dag vs. nacht)
- Onvoldoende gegevensverzamelingsduur
- Onbekende drempelwaarden voor adequaat gegevensvolume
Twee primaire factoren beïnvloeden vertrouwen: "de variatiebreedte in onze verzamelde gegevens, en de hoeveelheid verzamelde gegevens."
De Gegevensvariantie en Standaarddeviatie
Standaarddeviatie meet gegevensspreiding. "Een lage standaarddeviatie geeft aan dat de gegevenspunten de neiging hebben dicht bij het gemiddelde te liggen, en vice versa."
import numpy as np
np.random.normal(10, 1, 500)
np.random.normal(10, 3, 500)
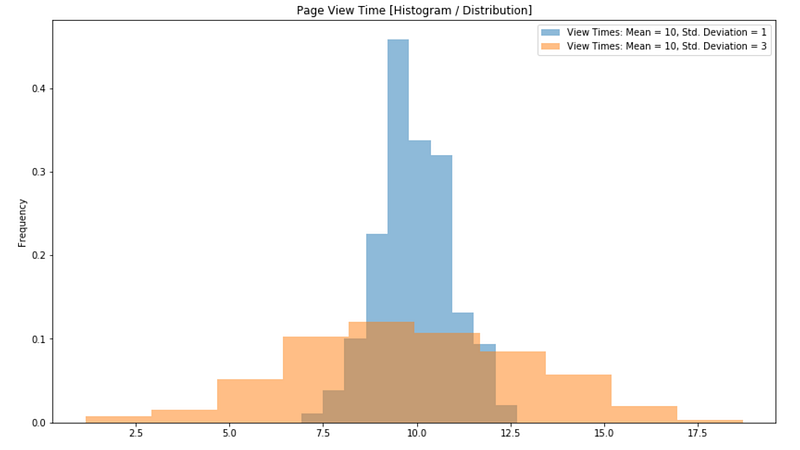
Datasets met lagere variantie rechtvaardigen groter vertrouwen in hun gemiddelde schattingen in vergelijking met tegenhangers met hogere variantie.
De Grootte van de Gegevens (N)
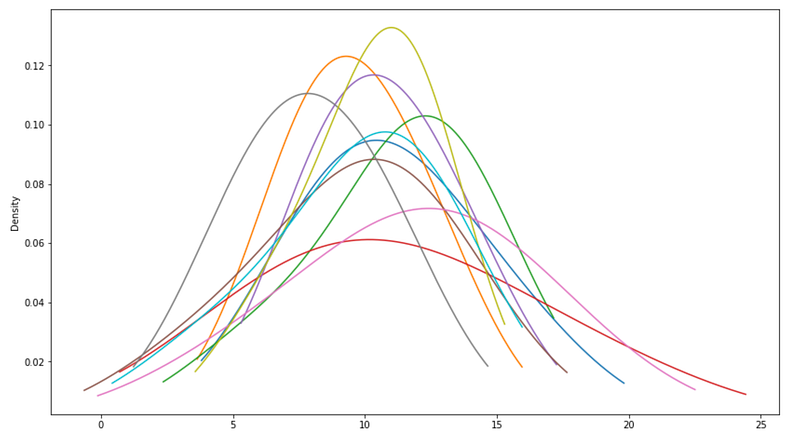
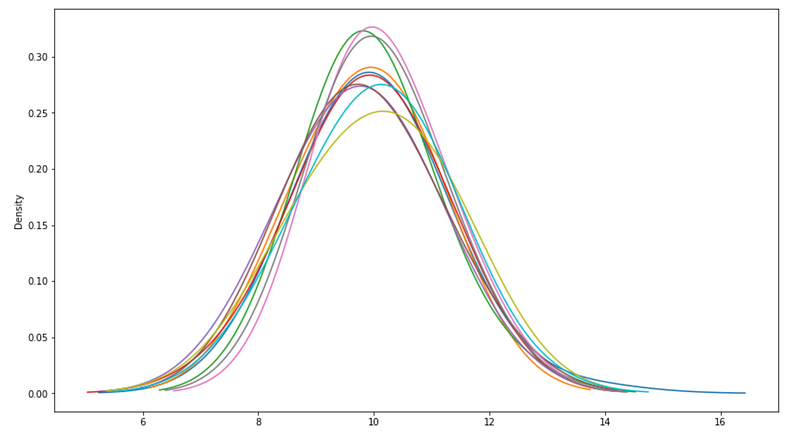
Steekproefgrootte beïnvloedt de stabiliteit van het gemiddelde dramatisch. Kleine steekproeven produceren zeer variabele gemiddelden, terwijl grote steekproeven convergeren naar populatieparameters.
import numpy as np
import pandas as pd
import matplotlib as plt
for _ in range(10):
pd.Series(np.random.normal(10, 3, 5)).plot(
kind='kde',
bw_method=1,
ax=ax
)
Standaardfout
Standaardfout combineert de effecten van variantie en steekproefgrootte:
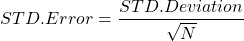
De formule: SE = Standaarddeviatie / wortel(Steekproefgrootte)
sample1 = pd.Series(np.random.normal(10, 1, 5))
sample2 = pd.Series(np.random.normal(10, 1, 50))
sample3 = pd.Series(np.random.normal(10, 9, 5))
sample4 = pd.Series(np.random.normal(10, 9, 50))
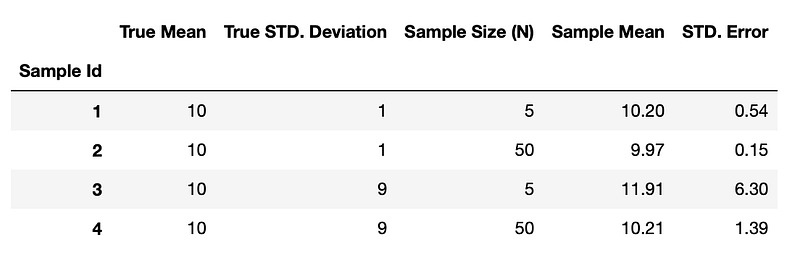
df['Sample Mean'].plot(kind='bar', yerr=df['STD. Error'])
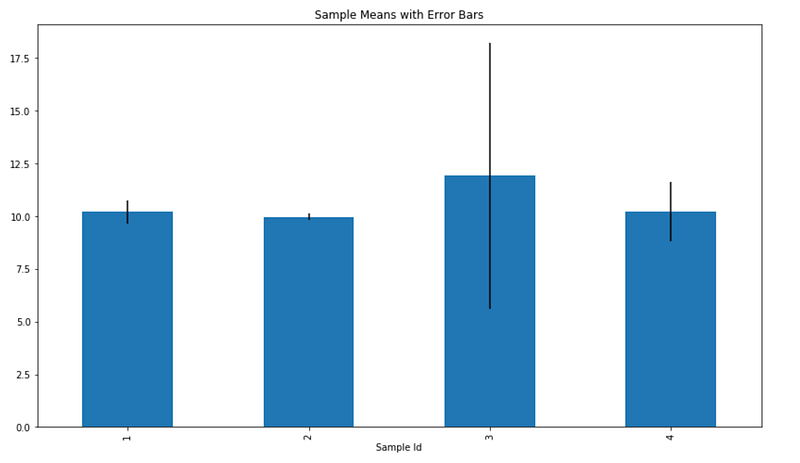
Bredere foutbalken signaleren verminderd vertrouwen in geschatte waarden.
Betrouwbaarheidsintervallen
In plaats van willekeurig vermenigvuldigers te selecteren, vertrouwen betrouwbaarheidsintervallen op statistische principes. Normale verdelingen vertonen voorspelbare patronen: ongeveer 68% van de gegevens valt binnen één standaarddeviatie, en ongeveer 95% binnen twee standaarddeviaties.
Z-Scores stellen betrouwbaarheidsdrempels vast:
- Z = 1: ~68% betrouwbaarheid
- Z = 1,96: 95% betrouwbaarheid
- Z = 2,58: 99% betrouwbaarheid
Het 95% betrouwbaarheidsinterval beslaat: Gemiddelde +/- (1,96 x Standaardfout)
T-Scores dienen als alternatieven voor Z-Scores onder bepaalde omstandigheden.
Hoe Zit Het Met Niet-Normale Gegevens?
Belangrijkste conclusie: "Maak je geen zorgen als je gegevens niet uit een normale verdeling komen, behandel ze gewoon alsof dat wel zo is en je komt er wel!"
De Centrale Limietstelling stelt dat steekproefgemiddelden normale verdelingen volgen, ongeacht onderliggende gegevensverdelingsvormen, mits steekproeven voldoende groot zijn. Dit principe is echter minder betrouwbaar voor medianen en kwartielen.
Conclusie
Beoefenaars moeten prioriteit geven aan het berekenen van standaardfouten en het afbeelden van foutbalken rond samenvattende statistieken. Terwijl wetenschappelijke publicaties deze praktijk regelmatig toepassen, lopen zakelijke contexten achter. Dataprofessionals moeten belanghebbenden ofwel onderwijzen over het interpreteren van foutbalken of persoonlijk ervoor zorgen dat vertrouwensbeoordelingen hun aanbevelingen informeren.

Tarek Amr, 5 april 2021