مقدمة لطيفة لفترات الثقة
كتير من المتقدمين لوظايف تحليل البيانات ناقصهم فهم مفاهيم إحصائية أساسية. في الشغل، محلل البيانات بيجمع معلومات، بيحسب أرقام ومتوسطات، وبعدين بيروح يقول لصاحب القرار "دي النتيجة اللي طلعت معايا".
إنت واثق كفاية في الأرقام اللي طلعت معاك؟
تخيل معايا إنك بتشتغل في موقع بيع أونلاين أو تطبيق. عايز تعرف الناس بتقضي قد إيه وقت على الموقع قبل ما يشتروا حاجة.
جمعت بيانات من 500 زيارة (دي اللي بنسميها "جلسات" أو sessions - يعني كل مرة حد يفتح الموقع ويتصفح فيه). حسبت المتوسط، طلع إن الناس في المتوسط بتقضي 10 دقايق على الموقع.
دلوقتي السؤال: ممكن تبقى واثق قد إيه في الرقم ده؟ يعني هل فعلاً كل الناس بتقضي حوالي 10 دقايق، ولا ممكن يكون فيه مشكلة في البيانات اللي جمعتها؟
المخاوف اللي ممكن تقلقك:
- العينة مش ممثلة بالصدفة: يمكن الـ 500 زيارة دول كلهم من نفس النوع من الناس، مش ممثلين كل عملاءك
- توقيت جمع البيانات: يمكن جمعت البيانات في الويك إند بس، أو في النهار بس، والناس بتتصرف مختلف في أوقات مختلفة
- المدة قليلة: يمكن محتاج تجمع بيانات لفترة أطول
- العدد قليل: مش عارف 500 زيارة كفاية ولا لأ؟
فيه عاملين أساسيين بيحددوا قد إيه ممكن تثق في النتائج بتاعتك: قد إيه البيانات متفاوتة عن بعضها، وقد إيه عدد البيانات اللي جمعتها كبير.
تباين البيانات والانحراف المعياري
الانحراف المعياري (Standard Deviation) بيقيس قد إيه البيانات متباعدة عن بعضها.
تخيل معايا سيناريوهين:
سيناريو 1: كل الزوار بيقضوا وقت قريب من بعضه - واحد 9 دقايق، التاني 10 دقايق، التالت 11 دقيقة. المتوسط 10 دقايق والبيانات كلها قريبة من بعض. في الحالة دي، الانحراف المعياري صغير وإنت تقدر تثق أكتر إن المتوسط فعلاً بيمثل الواقع.
سيناريو 2: في ناس بتقضي دقيقة واحدة بس (دخلت وخرجت بسرعة)، وناس تانية بتقضي ساعة كاملة (قاعدة تتصفح وتقارن). المتوسط برضه ممكن يطلع 10 دقايق، بس البيانات متشتتة جداً. هنا الانحراف المعياري كبير وإنت لازم تكون أقل ثقة في المتوسط ده.
import numpy as np
np.random.normal(10, 1, 500) # انحراف معياري صغير = 1
np.random.normal(10, 3, 500) # انحراف معياري كبير = 3
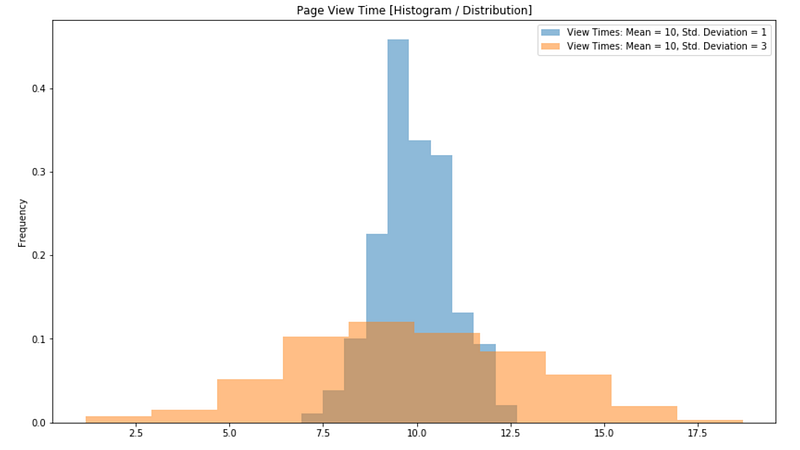
القاعدة بسيطة: لما البيانات قريبة من بعضها (انحراف معياري صغير)، تقدر تثق في المتوسط أكتر. لما البيانات متشتتة (انحراف معياري كبير)، لازم تاخد بالك.
حجم البيانات (N)
عدد البيانات اللي بتجمعها مهم جداً.
تخيل إنك عايز تعرف نسبة التحويل (Conversion Rate) في موقعك - يعني من كل 100 واحد بيزوروا الموقع، كام واحد بيشتري فعلاً.
لو جمعت بيانات من 5 زوار بس: ممكن واحد منهم يشتري (20%) أو اتنين (40%) أو حتى محدش يشتري (0%). النتيجة هتتغير جداً من يوم للتاني، ومش هتقدر تعتمد عليها.
لو جمعت بيانات من 5000 زائر: النسبة هتستقر حوالين رقم معين (مثلاً 15%)، ومش هتتغير كتير لو جمعت 5000 زائر تانيين.
import numpy as np
import pandas as pd
import matplotlib as plt
# تجربة مع 5 عينات بس
for _ in range(10):
pd.Series(np.random.normal(10, 3, 5)).plot(
kind='kde',
bw_method=1,
ax=ax
)
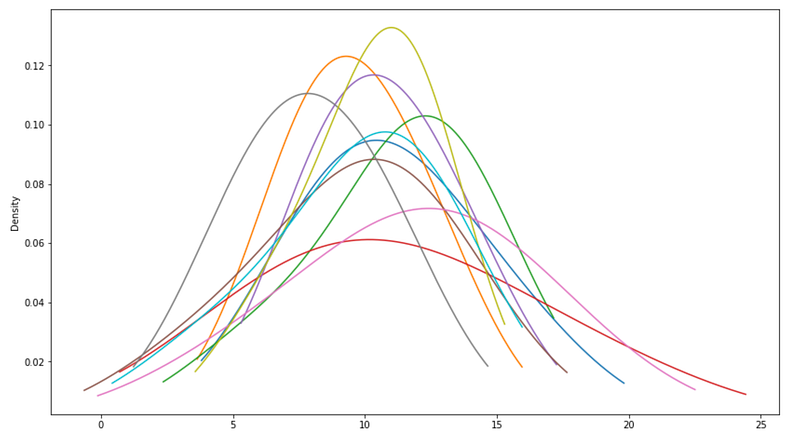
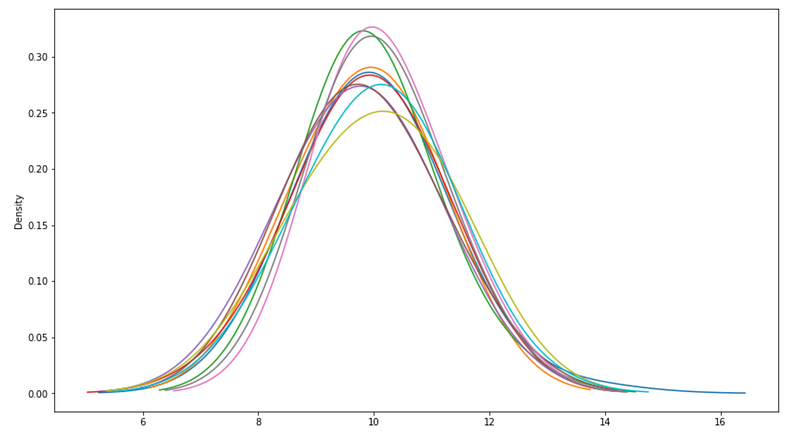
كل ما تجمع بيانات أكتر، كل ما النتائج تبقى أدق وأثبت.
الخطأ المعياري (Standard Error)
دلوقتي نجمع العاملين دول مع بعض في رقم واحد اسمه الخطأ المعياري:
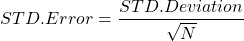
المعادلة: الخطأ المعياري = الانحراف المعياري ÷ الجذر التربيعي لعدد البيانات
يعني:
- لو البيانات متشتتة (انحراف معياري كبير) → الخطأ المعياري بيكبر → ثقتك بتقل
- لو البيانات قليلة (عدد صغير) → الخطأ المعياري بيكبر → ثقتك بتقل
- لو البيانات قريبة من بعض (انحراف معياري صغير) → الخطأ المعياري بيصغر → ثقتك بتزيد
- لو البيانات كتيرة (عدد كبير) → الخطأ المعياري بيصغر → ثقتك بتزيد
sample1 = pd.Series(np.random.normal(10, 1, 5)) # قليلة ومتقاربة
sample2 = pd.Series(np.random.normal(10, 1, 50)) # كتيرة ومتقاربة
sample3 = pd.Series(np.random.normal(10, 9, 5)) # قليلة ومتشتتة
sample4 = pd.Series(np.random.normal(10, 9, 50)) # كتيرة ومتشتتة
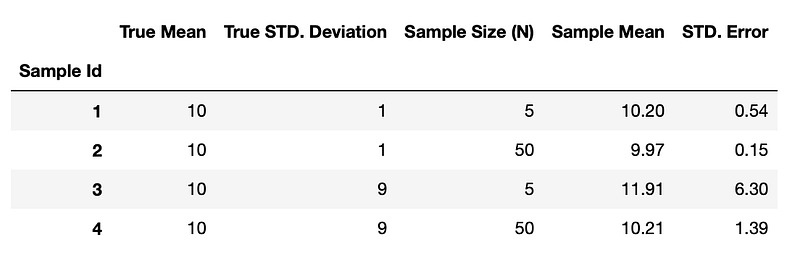
df['Sample Mean'].plot(kind='bar', yerr=df['STD. Error'])
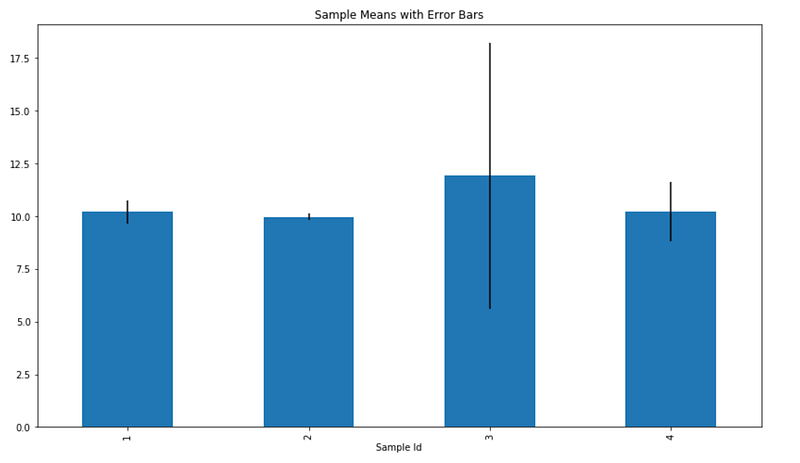
الخطوط اللي فوق وتحت كل عمود دي اسمها أشرطة الخطأ (Error Bars). كل ما الشريط يكون أطول، كل ما ثقتك في الرقم تكون أقل.
فترات الثقة (Confidence Intervals)
دلوقتي نوصل للجزء المهم: إزاي تقول لمديرك إنك واثق في النتائج بنسبة كام؟
بدل ما تقول "المتوسط 10 دقايق" وخلاص، الأحسن تقول: "أنا واثق بنسبة 95% إن المتوسط الحقيقي بين 8 و 12 دقيقة". دي اللي بنسميها فترة الثقة.
الموضوع بيعتمد على حقيقة إحصائية: في معظم البيانات، حوالي 68% من القيم بتقع قريبة من المتوسط (في حدود انحراف معياري واحد)، و95% بتقع في حدود انحرافين معياريين.
عشان نحسب فترة الثقة، بنستخدم أرقام ثابتة اسمها Z-Scores:
- Z = 1: تقدر تقول إنك واثق بنسبة ~68%
- Z = 1.96: تقدر تقول إنك واثق بنسبة 95% (الأشهر والأكتر استخداماً)
- Z = 2.58: تقدر تقول إنك واثق بنسبة 99%
الحساب:
فترة الثقة 95% = المتوسط ± (1.96 × الخطأ المعياري)
مثال عملي: لو المتوسط 10 دقايق، والخطأ المعياري 1 دقيقة:
- فترة الثقة = 10 ± (1.96 × 1) = 10 ± 1.96
- يعني إنت واثق 95% إن المتوسط الحقيقي بين 8.04 و 11.96 دقيقة
في حالات معينة (لما البيانات قليلة جداً)، بنستخدم T-Scores بدل Z-Scores، بس المبدأ نفسه.
طيب لو البيانات بتاعتي مش "طبيعية"؟
ممكن تقول: "بس يا عم الحاج، أنا بياناتي مش زي المنحنى الجميل ده! عندي ناس بتشتري كتير وناس بتشتري شوية، مش توزيع طبيعي!"
الإجابة: متقلقش خالص!
فيه نظرية في الإحصاء اسمها نظرية النهاية المركزية (Central Limit Theorem) بتقول حاجة سحرية: حتى لو البيانات الأصلية مش طبيعية، المتوسطات بتبقى طبيعية!
يعني حتى لو بيانات مبيعاتك أو زياراتك شكلها غريب، طول ما عندك عدد كافي من البيانات (عادةً 30 نقطة بيانات أو أكتر)، تقدر تستخدم نفس الحسابات اللي فاتت وتطلع بفترات ثقة صحيحة.
ملحوظة مهمة: النظرية دي بتشتغل كويس جداً مع المتوسطات، لكن مش دايماً بتشتغل كويس مع الوسيط (Median) أو الـ Percentiles.
الخلاصة
النصيحة العملية: لما تحسب أي رقم من بياناتك (متوسط وقت الزيارة، نسبة التحويل، متوسط سعر الشراء، إلخ)، متكتفيش بالرقم لوحده.
دايماً احسب واعرض:
- الخطأ المعياري (Standard Error)
- فترة الثقة (Confidence Interval)
- أشرطة الخطأ (Error Bars) على الرسومات
ليه؟
تخيل إنك بتقول لمديرك: "نسبة التحويل في الموقع 15%". مديرك هيفكر إن دي حقيقة مطلقة.
لكن لو قلتله: "نسبة التحويل 15%، وأنا واثق 95% إنها بين 13% و 17%"، ده بيدي صورة أوضح وبيساعد في اتخاذ قرارات أحسن.
للأسف: المنشورات العلمية دايماً بتستخدم فترات الثقة دي، لكن في الشركات والأعمال ناس كتير بتتجاهلها.
دورك كمحلل بيانات: يا تعلم الناس إزاي يفهموا أشرطة الخطأ دي، يا على الأقل إنت شخصياً ماتنساش تحسبها قبل ما تدي أي توصية.

متنساش: مش كل رقم أكيد، وفيه فرق بين "المتوسط اللي طلع معاك" و "المتوسط الحقيقي اللي موجود في الواقع". فترات الثقة بتساعدك تعرف قد إيه ممكن تكون قريب من الحقيقة.
طارق عمرو، 5 أبريل 2021