Kaplan-Meier Survival Analyse
En hoe deze niet-parametrische benadering wordt gebruikt om de survival functie te fitten.
Ik legde survival analyse uit in een eerdere post. Als je geen zin hebt om nog een post te lezen, hier is de essentie:
Wanneer je doelen er heel lang over doen om beschikbaar te zijn voor je om te modelleren met een Regressiemodel, kun je in plaats daarvan de Survival Analyse gebruiken.
In deze alternatieve benadering, in plaats van een puntschatting (het doel) te voorspellen, voorspel je een functie van dat doel in tijd (de survival functie of survival curve).
Het voordeel van deze benadering is dat je allerlei soorten premature gegevens kunt gebruiken om je curve te fitten, en je hoeft niet te wachten tot het laatste punt op de curve beschikbaar is voordat je je model bouwt.
Ik vermeldde kort in de vorige post dat er verschillende parametrische en niet-parametrische methoden zijn voor het fitten van de survival curve. Een van deze methoden is de Kaplan-Meier schatter. Toen werd me gevraagd om het in detail uit te leggen in een aparte post. Dus hier zijn we met onze nieuwe vrienden, Edward Kaplan en Paul Meier.
Maar eerst, laten we het verschil uitleggen tussen de parametrische en de niet-parametrische methoden.
Opmerking: Voel je vrij om naar de Kaplan-Meier survival functie schattingssectie te springen als je al weet over de Parametrische vs Niet-parametrische Methoden
Parametrische vs Niet-parametrische Methoden
Stel je voor dat je het volgende wilt modelleren:
Je hebt een TV-show die draait op je app, en je wilt modelleren hoeveel van je gebruikers deze in de loop van de tijd blijven volgen. In het begin begonnen ze allemaal de show te volgen. Dan beginnen sommigen van hen in de loop van de tijd af te haken.
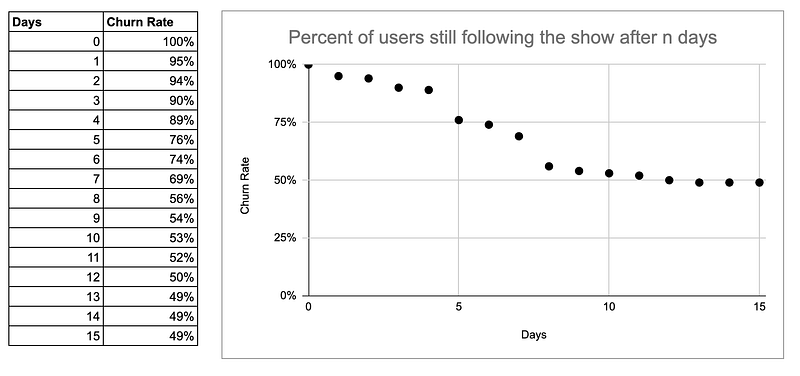
Breed gesproken, om een functie te vinden om die punten hierboven weer te geven, kun je ofwel een parametrische of een niet-parametrische benadering volgen.
De parametrische benadering van curve fitting
In de parametrische methode neem je aan dat je datapunten een specifieke vorm volgen, die je van tevoren moet beslissen.
Zeg, je besluit dat je gegevens een exponentiële functie volgen. Je weet dat deze functie bepaalde parameters heeft. Dus alles wat je hoeft te doen is de beste parameters te vinden die je een curve geven die zo dicht mogelijk bij je datapunten ligt.
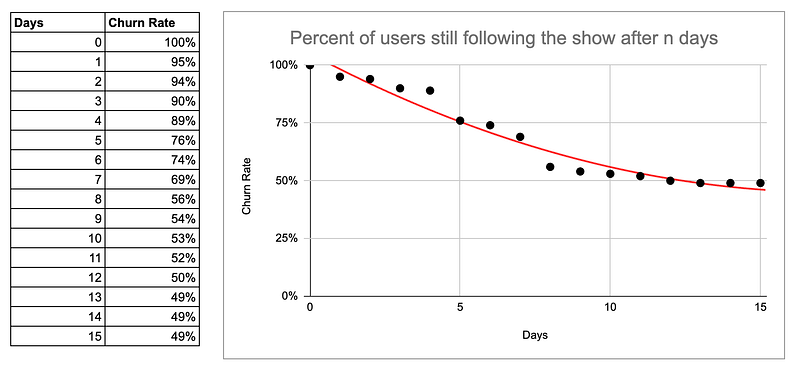
Het vinden van de juiste parameters wordt curve fitting genoemd.
Het kiezen van een andere functie met andere parameters zal resulteren in een andere curve. Zie wat er gebeurt wanneer een andere functie wordt gekozen.
(Grafiek: Een andere parametrische benadering voor het fitten van je datapunten)
Het kiezen van de juiste functie is hier van het grootste belang.
Omgekeerd kan het maken van een verkeerde aanname over de vorm van je gegevens leiden tot suboptimale resultaten, zoals je hieronder kunt zien:
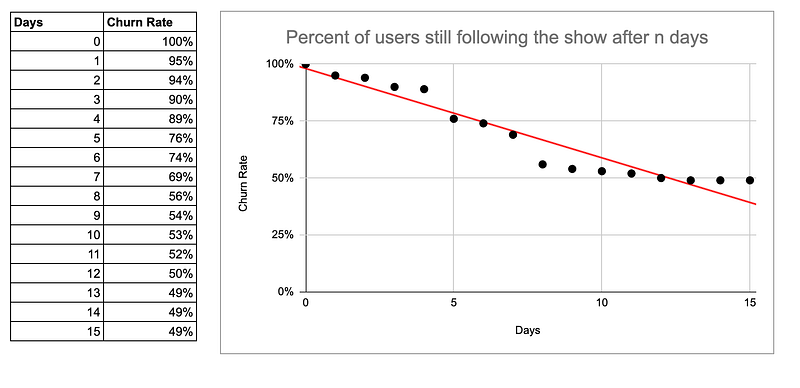
Als alternatief is er de niet-parametrische benadering.
De niet-parametrische benadering van curve fitting
In plaats van een specifieke wiskundige formule aan te nemen om de relatie tussen de invoer- en uitvoervariabelen te beschrijven, leren de niet-parametrische curve fitting methoden direct van de gegevens.
Denk eraan als het spelen van het "verbind de punten" spel in tijdschriften, waar je de datapunten plot en lijnen tekent om ze met elkaar te verbinden.
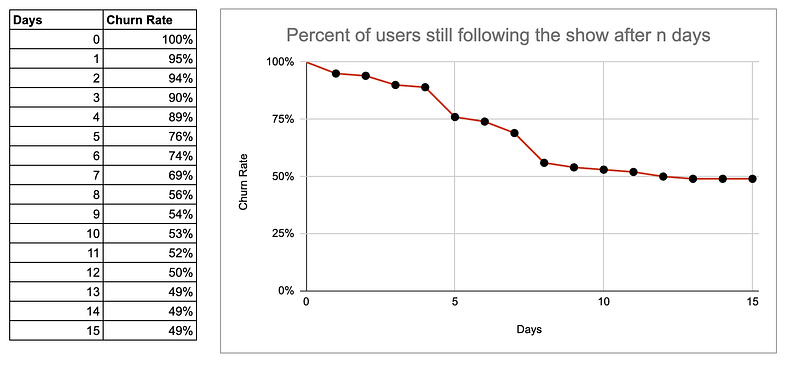
Klinkt te mooi om waar te zijn, hè? Waarom zou je je druk maken over curve fitting als we gewoon de punten kunnen verbinden?
Wel, de niet-parametrische benadering heeft inderdaad zijn nadelen. Het volgt de gegevens blindelings, à la overfitting. Vooral wanneer je weinig en rumoerige gegevens hebt.
In dergelijke gevallen kan het nuttig zijn om terug te keren naar de aannames van een parametrisch model om je model in de hand te houden.
Maar laten we bij onze niet-parametrische modellen blijven voor nu; hier hoort Kaplan-Meier thuis.
Kaplan-Meier survival functie schatting
Het belangrijkste punt van Kaplan-Meier schatting is dat het je in staat stelt survival functies te construeren voor verschillende gebruikersgroepen.
In ons voorbeeld van showkijkers kunnen we niet aannemen dat alle gebruikers zich tegelijkertijd hebben aangemeld; sommigen sloten zich 6 dagen geleden aan, anderen 4, en sommigen pas 2 dagen geleden.
Hoe kunnen we een 6-daagse survival curve maken als sommige van onze gebruikers er pas 4 of 2 dagen zijn geweest?
Enter Kaplan Meier:
Voor elke overgang van de ene dag naar de volgende, geven we alleen om de gebruikers die er waren vóór de overgang. We berekenen vervolgens de verhoudingen van gebruikers aan het einde van elke overgang tot degenen die ervóór aanwezig waren. Het product van deze verhoudingen levert onze survival functie op tijd t, d.w.z. S(t).
Maak je geen zorgen als het bovenstaande niet duidelijk is, het volgende voorbeeld zal het heel gemakkelijk maken!
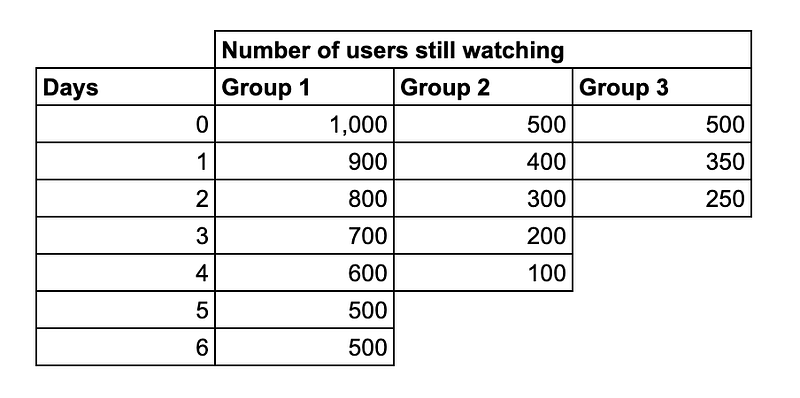
Bij stap nul hebben we 2.000 gebruikers, van alle drie de groepen. En per definitie overleven alle gebruikers nog op tijd 0, d.w.z. S(0) = 100%.
Dan bij stap 1 zijn er nog maar 1.650, d.w.z. 900 + 400 + 350. Dan is de kans op tijd 1 P(1) = 1650 / 2000 = 82,5%. En S(1) = S(0) * P(1) = 100% * 82,5% = 82,5%.
Evenzo hebben bij stap 2 1.350 deze overgang overleefd van de oorspronkelijke 1.650 gebruikers vóór de overgang, dus P(2) = 1350 / 1650 = 81,82%. En S(2) = S(1) * P(2) = 82,5% * 81,82% = 67,5%.
Nu is stap 3 lastig, groep 3 maakt geen deel meer uit van deze overgang, niemand van hen sloot zich meer dan 2 dagen geleden aan bij ons platform. Dus zullen we groep 3 negeren in onze berekening hier. Aan het begin van deze overgang hebben we 1.100 gebruikers van groepen 1 en 2, en na de overgang zijn er 900 over. Dus P(3) = 900 / 1100 = 81,82%. En de survival functie bij t=3 gaat S(3) = S(2) * P(3) = 67,5% * 81,82% = 55,23% zijn.
de survival functie bij t=4 is gemakkelijk, probeer het zelf en je krijgt S(4) = 42,95%. Nu, bij stap 5, hebben we opnieuw nog een groep verloren, dus P(5) = 500 / 600 = 83,33%, en S(5) = S(4) * P(5) = 42,95% * 83,33% = 35,8%. En voor het geval je nieuwsgierig bent, S(6) = 35,8% ook, aangezien P(6) = 100%, alle gebruikers aan het begin van deze stap bleven tot het einde.
Wat ons uiteindelijk de volgende survival functie geeft.
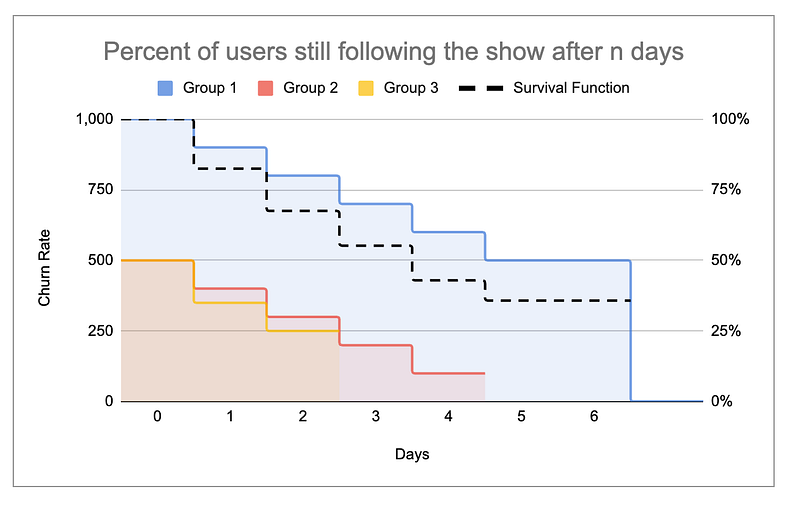
De Kaplan Meier survival curve wordt meestal geplot in de vorm van een stapfunctie. De tijd is hier discreet, en je kent alleen de waarde van S(t) op die discrete tijden.
Dat is het!
Voor de Pythonista's onder jullie, ik raad de lifelines bibliotheek aan van Cam Davidson-Pilon. Het is een schone en eenvoudig te gebruiken bibliotheek.
En als je in een andere omgeving werkt, heb ik ook Kaplan Meier zelf geïmplementeerd in omgevingen waar ik lifelines niet kon gebruiken, en het was eenvoudig om te implementeren zoals je kunt zien.
Tarek Amr, 16 april 2024