Wanneer Survival Analyse te Gebruiken in Plaats van Regressie?
"En wat is een Survival functie?", hoorde ik je vragen
Regressie is een belangrijk item in elke Data Scientist's gereedschapskist. Je gebruikt het waarschijnlijk de hele tijd; en dat zou je ook moeten doen. Maar soms is het niet het juiste gereedschap voor de klus.
Hier is een voorbeeld om je te laten zien waarom:
Je wilt de hoogte van een golfbal voorspellen na 5 meter, gegeven de techniek van de speler, de kracht van hun schot en, zeg, de windsnelheid. Hoe zou je het schatten?
Regressie, zeg je?
Correct!
Nu, wat als ik je vertelde: om de een of andere reden stond er een koelkast in de weg van je golfers.
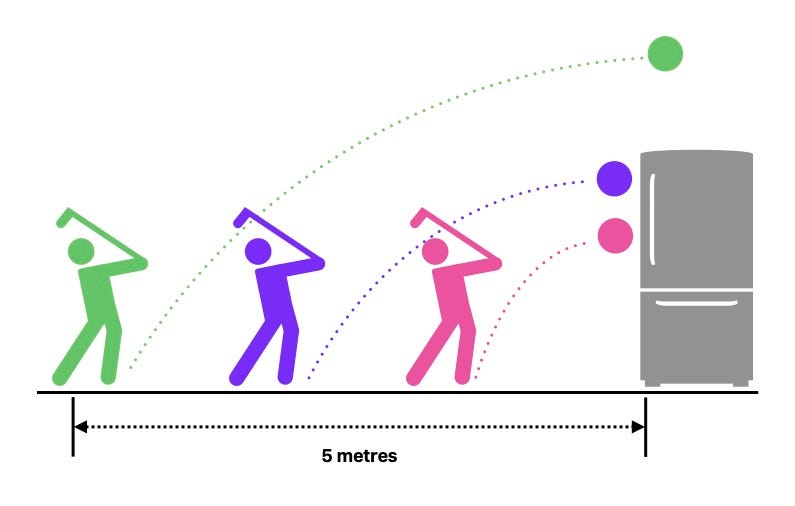
Je wenst dat die nare koelkast er niet was, het heeft niets te maken met je experiment.
Jammer, je moet ermee dealen.
En sorry, je krijgt niet de kans om dit experiment opnieuw te doen. Die kleurrijke golfers zijn nu te druk om je opnieuw te helpen.
Nu moet je buiten je gereedschapskist denken.
Optie Een: Ik gebruik toch nog steeds Regressie
Oké, je kunt zeker regressie gebruiken, maar je moet de paarse en de roze golfers uitsluiten. De koelkast stond in hun weg. Alleen de groene blijft over.
Te weinig samples om je regressiemodel op te baseren.
Geen goed idee!
Optie Twee: Pas het probleem aan om bij mijn experiment te passen
In plaats van de hoogte van de bal te voorspellen, hoe zit het met het voorspellen van het traject van de bal?
In plaats van een puntschatting (hoogte na 5 meter), ga je nu een functie h(d) voorspellen die de hoogte van de bal, h, versus alle mogelijke afstanden, d vertegenwoordigt.
Op deze manier zal niet alleen de groene golfer ons datapunten geven om op te trainen, helemaal tot 5 meter, maar ook de paarse en de roze golfer zullen ons extra datapunten geven. Niet tot 5 meter weliswaar, maar misschien tot 2 of 3 meter. Niet slecht, als je al deze informatie combineert om je h(d) te schatten.
Het goede aan deze benadering is dat je door h(d) te kennen deze functie als volgt kunt gebruiken: Je geeft het elke waarde van d en krijgt de verwachte hoogte terug op de gegeven afstand.
Dit, mijn vriend, is het sleutelconcept achter survival analyse, maar in plaats van de nare koelkast heb je het ongeduldig tikken van de tijd.
Survival analyse werd uitgevonden om het effect van medicijnen op patiënten te schatten.
Je geeft een groep patiënten een medicijn, en je wilt weten hoe lang ze daarna zullen leven (overleven).
Ik weet niet hoe het met jou zit, maar ik ben niet geduldig genoeg om 80 jaar te wachten tot alle patiënten zijn gestorven om mijn experiment af te ronden.
Dus, in plaats van een puntschatting (tijd tot overlijden), gaan we nu een Survival functie S(t) voorspellen die de kans vertegenwoordigt dat een patiënt overleeft tot tijd t.
Hoe worden Survival functies geschat?
Oké, tot nu toe is alles prima, maar hoe deze survival functie in tijd schatten, S(t)?
Er zijn meerdere benaderingen hiervoor, en we kunnen ze verdelen in parametrische en niet-parametrische benaderingen.
Parametrische Survival Functies
In deze benadering nemen we aan dat de survival functie een specifieke vorm heeft.
We weten dat alle patiënten in leven waren aan het begin van de experimenten, d.w.z. ze overleven allemaal nog op t=0, en dus S(0) = 1. We weten ook dat meer patiënten in de loop van de tijd sterven, dus S(t) neemt in de loop van de tijd af tot het nul bereikt, waar geen patiënten meer overleven. Eén functie die er zo uitziet is de volgende exponentiële vervalfunctie:
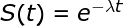
Nu hoef je alleen maar alle datapunten die je hebt verzameld te gebruiken om de waarde van λ te krijgen die deze functie laat passen bij je gegevens, d.w.z. curve fitting.
Er zijn meerdere functies die typisch worden gebruikt in survival analyse naast de exponentiële functie.
Als je aan kansverdelingen denkt, gaat hun CDF (cumulatieve distributiefunctie) van 0 naar 1, dit is het tegenovergestelde van survival functies die van 1 naar 0 gaan. Daarom worden survival functies als volgt gedefinieerd: S(t) = 1 - CDF. En de volgende verdelingen worden vaak gebruikt om survival functies af te leiden van hun CDF's: Weibull, Gamma, Log-Normal, en Log-Logistic.
Het belangrijkste probleem met deze benadering is dat we aannames maken over de vorm van de survival functie. Je nam al aan dat de survival functie eruit zal zien als een exponentiële verval en je wilt die functie dwingen om bij je gegevens te passen. Wat als het er niet bij past?
Niet-Parametrische Survival Functie
Deze andere benadering maakt geen aannames over de vorm van de survival functie. Bijvoorbeeld, in de Kaplan-Meier benadering bouwen we in principe een stapfunctie uit de verzamelde datapunten. Maar omdat het de functie empirisch bouwt, kan het niet simpelweg extrapoleren buiten de verzamelde datapunten. Dit is iets wat parametrische benaderingen wel kunnen doen.
Naast die twee statistische benaderingen kun je ook aan machine learning denken als een alternatieve methode. Elk model dat een curve voorspelt in plaats van puntschattingen zal de truc voor je doen.
Eindelijk, waar is deze Survival Analyse goed voor?
Voorbij Golfen en Stervende Patiënten
Je hebt geen patiënten om medicijnen aan te geven, en je bent gelukkig genoeg om geen koelkasten op je golfbaan te hebben. Waarom moet je nog steeds leren over de Survival Analyse?
Hetzelfde concept kan worden gebruikt om met veel problemen om te gaan waar gegevens niet compleet zijn om welke redenen dan ook. Dit probleem staat meestal bekend als right censoring. Bijvoorbeeld, je wilt het churn-percentage van je klanten meten, het percentage retourzendingen van je verkochte artikelen of de lifetime value van je shoppers. In al deze voorbeelden kun je eeuwen wachten om je doelwaarde te verzamelen, maar het bedrijf zal niet op je wachten om tot je conclusies te komen, en dus is de Survival Analyse hier voor je redding.
Tarek Amr, 24 januari 2024