Machine Learning & De Long Tail Paradox
Wanneer past automatisering bij jouw bedrijfsmodel?

Het is niet dat de telefoon niet scherp genoeg was om de sinaasappel te snijden, het is dat het niet het juiste gereedschap voor de klus is.
Meestal wanneer ML (machine learning) zijn zakelijke potentieel niet haalt, is het niet omdat je gegevens onvolledig zijn of je data scientists geen extraverte introverten zijn, of al die dingen. Het is meestal omdat ML niet het juiste gereedschap is voor jouw bedrijfsmodel.
In dit artikel wil ik de misalignments bespreken die kunnen ontstaan tussen bedrijven en hun automatiseringsinspanningen.
Tijdens het bespreken van een nieuw project vertelde mijn manager me dat kunstmatige intelligentie leeft in de long tail. Haar opmerking stuurde me om Chris Anderson's boek, The Long Tail, opnieuw te lezen.
Ik had een andere carrière toen ik het boek voor de eerste keer las. Deze keer las ik het en zijn kritiek vanuit een ander uitkijkpunt. En nu hielpen de analogieën die ik vond me te begrijpen wanneer ML bedrijfswaarde biedt, en wanneer het niet het juiste gereedschap voor de klus is. En ik hoop dat ik dit begrip hier met je kan delen.
Laat me beginnen met het opsommen van de belangrijkste conclusies van het boek.
Chris Anderson's Long-Tail Theorie
Wanneer retailers beperkte schapruimte hebben, kiezen ze ervoor om alleen de meest populaire artikelen daar te verkopen. Maar wanneer schapruimte en andere distributiekosten niet langer de beperkende factoren zijn, kunnen ze hun aanbod uitbreiden naar minder populaire niches, of de long-tail artikelen. Vandaar de naam van het boek.
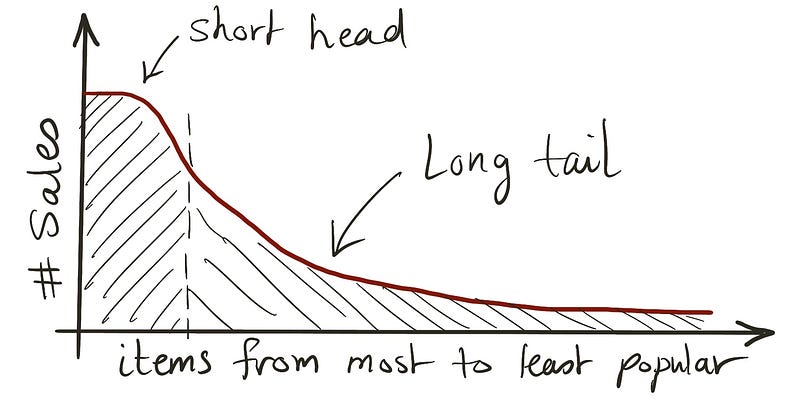
Bijvoorbeeld, toen het internet oneindige schapruimte bood voor retailers zoals Amazon, werd Amazon de alles-winkel.
Het is meer dan de schapruimte
Duidelijk is schapruimte niet de enige beperkende factor, er zijn meer krachten aan het werk hier. Het boek stelt dat de kosten voor consumenten om de long-tail artikelen te bereiken dalen door de volgende drie krachten:
- Democratisering van de productietools: Denk aan dropshipping en creator economy.
- Democratisering van de distributietools: Denk aan aggregators zoals Amazon en Airbnb.
- Verbinding van Vraag en Aanbod: Denk aan aanbevelingsalgoritmen en zoekmachines.
Dus, het begrijpen van deze drie krachten, en hoe automatisering in elk van hen past, is essentieel voor het begrijpen wanneer ML essentieel is voor een bedrijf. Dus, laten we beginnen met de eerste twee krachten gecombineerd.
Democratisering van Productie & Distributie
Het eerste geheim voor het creëren van een bloeiende long-tail is door alles beschikbaar te maken voor iedereen. Aggregators zoals YouTube of TikTok democratiseren niet alleen de productie, iedereen kan een video maken, maar democratiseren ook de distributie, door deze video's bereikbaar te maken of je nu op je laptop, iPhone of Google Chrome bent. Hetzelfde patroon bestaat overal:
- Drop-shipping + Amazon = Democratisering van Productie & Distributie
- Airbnb = Democratisering van Productie & Distributie
- Uber = Democratisering van Productie & Distributie
- Wikipedia = Democratisering van Productie & Distributie
- Medium = Democratisering van Productie & Distributie
En de lijst gaat maar door en door.
Nu kun je vragen: "Waarom is automatisering hier nodig?"
Voor elk artikel dat je aanbiedt als aggregator, zijn er overheadkosten. Misschien moet je leveranciers betalen om elk artikel naar je magazijn te verzenden. Misschien betaal je voor het opslaan ervan. Misschien heb je een minimale kwaliteit, en wil je elk artikel controleren voordat je het accepteert. Misschien wil je deze artikelen categoriseren, beschrijvingen ervoor schrijven en die beschrijvingen vertalen. Deze extra kosten zijn min of meer vast per artikel. Maar wanneer je naar de long-tail grafiek kijkt, zul je merken dat inkomsten per artikel variëren. Dit betekent dat je ROI (return on investment) ook per artikel varieert.
Deze variatie bestaat wanneer je jezelf beperkt tot de short-head, maar wanneer de long-tail het spel is, wordt de ROI-variatie extreem. Artikelen aan het einde van de staart worden misschien nooit verkocht, maar je moet nog steeds hun overheadkosten dragen.
Deze extreme variatie in ROI betekent dat je ofwel bij de short-head arena blijft, of manieren vindt om de kosten van het aanbieden van elk artikel naar nul te brengen. En automatisering is een belangrijk hulpmiddel als je voor de tweede optie kiest.

Bedrijven die bij de short-head arena blijven, kunnen zich veroorloven om dingen handmatig te doen. Als het allemaal gaat om de meest populaire artikelen, dan is het hebben van een team dat elk artikel handmatig controleert gerechtvaardigd, en hun ROI zal meestal positief zijn. En als een artikel niet goed presteert, kun je het gewoon uit je inventaris verwijderen.
Eigenlijk zou ik deze bedrijven adviseren om hun automatiseringsinspanningen minimaal te houden, aangezien de kosten van automatisering op kleine schaal de kosten van handmatig werk zullen overschrijden. Je kunt zien wat ik bedoel in de bovenstaande afbeelding.
Maar zodra je inventaris voorbij de populaire artikelen gaat, moet je een mix van automatisering, machine learning en door gebruikers gegenereerde inhoud adopteren. Dan zal de lineaire groei van handmatige kosten de initiële investering in automatisering overschrijden.
De probabilistische leeftijd paradox
Het is moeilijk om kwaliteit te definiëren, aangezien het, net als schoonheid, in het oog van de beschouwer ligt. Toch varieert kwaliteit over het algemeen veel meer in de long-tail dan in de short-head. Anderson verwees naar het tijdperk waarin kwaliteit zo veel varieert als de probabilistische leeftijd.
"Met probabilistische systemen is er alleen een statistisch niveau van kwaliteit, wat wil zeggen: Sommige dingen zullen geweldig zijn, sommige dingen zullen middelmatig zijn, en sommige dingen zullen absoluut waardeloos zijn" — Chris Anderson
Hij gebruikte Wikipedia om zijn argument duidelijker te maken.
"Het punt is niet dat elk Wikipedia-item probabilistisch is, maar dat de hele encyclopedie zich probabilistisch gedraagt. Je kansen om een substantieel, actueel en nauwkeurig item te krijgen voor een bepaald onderwerp zijn uitstekend op Wikipedia, zelfs als niet elk individueel item uitstekend is" — Chris Anderson
En hier komt de paradox:
Nassim Nicholas Taleb vergeleek twee gevallen: Gevallen waar individuele items min of meer hetzelfde zijn, noemt hij deze Mediocristan. En gevallen waar items zo veel variëren, noemt hij deze Extremistan.
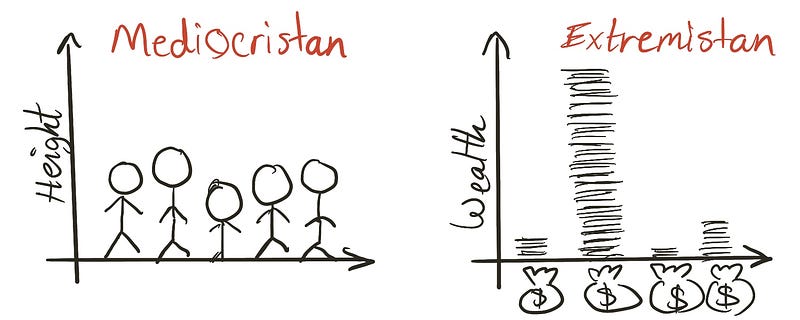
De lengtes van mensen is een voorbeeld van Mediocristan. In een klas van 10-jarige studenten hebben ze allemaal vergelijkbare lengtes. En daarom als je hun gemiddelde lengte gebruikt om de lengte van een nieuwe student te voorspellen, zul je niet zo veel ernaast zitten. Daarom zijn voorspellingen gemakkelijk in Mediocristan. De rijkdom van mensen is een voorbeeld van Extremistan. Veel succes met het gebruiken van het wereldwijde mediaan inkomen om Jeff Bezos' rijkdom te voorspellen.
Zoals we net hebben besproken, behoort de kwaliteit van de artikelen in de long-tail tot Extremistan. Dus aan de ene kant hebben we automatisering nodig om met deze artikelen om te gaan, maar aan de andere kant zijn voorspellingen daar moeilijker aangezien ze burgers van Extremistan zijn.
Dit is de paradox waar machine learning engineers mee moeten dealen. Hun werk is het meest nodig wanneer het moeilijker te doen is.
Martin Casado en Matt Bornstein lijken het eens te zijn, en ze bieden advies aan beoefenaars voor wanneer ze met long-tails te maken hebben. Desalniettemin is het meestal het geval dat in een long-tail wereld, iedereen comfortabel moet worden met het omgaan met kansen.
De machine learning algoritmen die in de long-tail worden gebruikt, zijn niet altijd zelfverzekerd. Daarom moeten de daar gebouwde modellen vertrouwen op kansen. Samen met hun voorspellingen retourneren ze extra waarden om hun vertrouwensniveau in hun eigen voorspelling te tonen.
Het slechte nieuws: mensen zijn niet erg goed in het omgaan met kansen. Maar het goede nieuws: je klanten zijn veel beter in het omgaan met kansen dan je zakelijke belanghebbenden.
Iedereen weet dat er een kans is dat het artikel dat ze gisteren op Wikipedia hebben gecontroleerd twee seconden eerder zou kunnen zijn gevandaliseerd. Ze weten het, en ze gaan ermee om, maar je zakelijke belanghebbenden leven misschien in een ideale wereld die niet bestaat. Daarom is als machine learning engineer, bij het omgaan met de long-tail, het moeilijkste deel van je baan niet om je voorspellingen nuttig te maken, maar om de verschillende belanghebbenden bij je bedrijf te overtuigen om deze voorspellingen in de eerste plaats te gebruiken. En dus is gebruikersexperimentatie je nummer één vriend.
Verbinding van Vraag en Aanbod
Met de toename van het aanbod en de hoge variatie in zijn kwaliteit hebben klanten hulp nodig om te vinden wat ze willen.
Natuurlijk wil iedereen het beste ter wereld, maar er zijn twee besten: Het is ofwel wat iedereen ziet als het beste, of wat het beste voor jou is. De eerste kan worden gevonden in de short-head, terwijl de laatste in de long-tail is. Lijsten zoals "de meest verkochte artikelen" geven je de eerste, maar je hebt een goede aanbevelingsmotor nodig om bij de laatste te komen.
Opnieuw ontmoeten we dezelfde paradox: ML-algoritmen en aanbevelingssystemen zijn nodig in de long-tail, maar de hoge variantie daar maakt het moeilijk voor de algoritmen om goed te presteren. Dit is waarom de algemene wijsheid onder beoefenaars stelt dat aanbevelingssystemen meestal moeite hebben om een eenvoudig systeem te verslaan dat alleen de meest populaire artikelen aanbeveelt.
Als aanbevelingssystemen moeilijk zijn, en het aanbevelen van de meest populaire artikelen gewoon werkt, waarom zou je dan moeite doen om een geavanceerd aanbevelingssysteem te bouwen en te verbeteren?
Dit is een geldige vraag, die elk bedrijf zichzelf zou moeten stellen. Ze moeten begrijpen dat aanbevelingsmotoren niet alleen een feature zijn om aan hun producten toe te voegen, maar ze moeten er strategisch over nadenken. Dit zijn twee strategische redenen om een aanbevelingsmotor te bouwen bij het omgaan met de long-tail:
- Commoditisering van leveranciers
- Oneindig aanbod voor de aandachtseconomie
Commoditisering van leveranciers
Wat aggregators onderscheidt van ouderwetse marktplaatsen is dat ze alles-winkels zijn, waarvan de merken groter zijn dan de merken van hun leveranciers. Je gaat naar Amazon vanwege het merk van Amazon, niet vanwege de naam van deze of die verkoper daar. In technische termen commoditiseren aggregators hun leveranciers, en een aanbevelingsmotor is onderdeel van deze commoditiseringsinspanning.
In Spotify's wereld luisteren we niet naar artiesten maar naar lijsten. We kunnen geen bepaalde chauffeur kiezen bij Uber of een specifieke huiseigenaar bij Airbnb. Je klikt op het eerste resultaat op Google, omdat het het eerste resultaat is, en niet omdat het van een specifieke website komt. Je kunt meer lezen over Ben Thompson's Aggregation Theory om te zien hoe aggregators hun leveranciers commoditiseren.
Aan de andere kant betekent het opgeven van gepersonaliseerde aanbevelingen en terugvallen op het suggereren van de meest populaire artikelen, dat je je leveranciers helpt om groter te worden dan jij, en tenzij je hun distributiekanalen bezit, zullen hun klanten ze op een andere manier bereiken en jou omzeilen.
Oneindig aanbod voor langdurige aandacht
Facebook is gratis. YouTube is meestal gratis. Ze worden gemonetiseerd door advertenties. Dus hebben ze nodig dat je meer scrolt, meer kijkt, en hoe meer je consumeert, hoe meer inkomsten ze maken.
Dus de enige manier om je aan het consumeren te houden is om je oneindig aanbod te bieden dat bij je smaak past. Ze moeten de long-tail verkennen om aan hun oneindige aanbodbehoeften te voldoen, en ze hebben een aanbevelingsalgoritme nodig om daar dingen te vinden die bij de smaak van elke gebruiker passen.
Abonnementsservices willen ook de kleefkracht van hun product verhogen door te pushen voor oneindig aanbod.
Samenvatting
Samenvattend bestaat er een nieuw soort distributiekanaal en staan bekend als aggregators.
- Wanneer aggregators moeten groeien, moeten ze de long-tail verkennen.
- Om dat te doen, moeten ze iedereen toestaan om een producent te worden.
- Bouw vervolgens manieren om elke consument te matchen met de niches die ze leuk vinden.
Wanneer iedereen een producent is, varieert kwaliteit. Zelfs als het moeilijk is om kwaliteit te meten, varieert ten minste het financiële rendement van elk artikel. Dit heeft de volgende impact op de behoefte om te automatiseren:
- De aggregators moeten alle kosten met betrekking tot unieke voorraadartikelen verminderen via automatisering. Typisch is ML het geschikte hulpmiddel voor automatisering.
- Het oneindige aanbod van artikelen betekent ook dat machine learning opnieuw nodig is om aanbevelingsalgoritmen te creëren.
Ten slotte, hoewel bedrijven die in de short-head leven automatisering nodig hebben om operaties te optimaliseren die schalen met hun klantenbasis en totale voorraadgrootte, kunnen ze wegkomen zonder automatisering voor alles dat schaalt met het aantal unieke voorraadartikelen.
Tarek Amr, 18 augustus 2021