Wanneer gebruik je de Binomiale versus Beta-verdeling?
En wat is het punt van kansverdeling eigenlijk?
Een voetballer staat erom bekend 70% van de penalty's die hij neemt te scoren. In het volgende seizoen verwachten we dat hij 10 penalty's zal nemen, hoeveel daarvan zal hij scoren?
Hij zal 7 van de 10 penalty's scoren, natuurlijk!
Eigenlijk is 10 penalty's een heel klein aantal om een definitieve conclusie uit te trekken. Deze vanzelfsprekende 7 zou met een beetje geluk 8 of 9 kunnen worden, of hij kan een paar onverwachte penalty's missen en de 7 wordt 5. Vanzelfsprekend, hè?
Met zo'n klein aantal zijn er nauwelijks vanzelfsprekende antwoorden, we moeten ons geloof eerder uitdrukken in de vorm van een verdeling.
En in dit geval is het een binomiale verdeling die we nodig hebben.
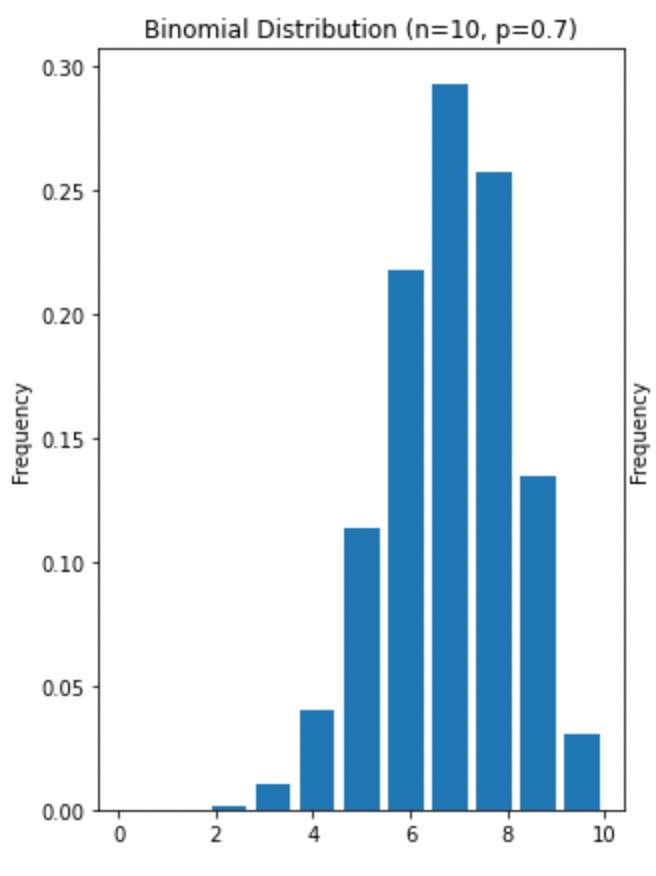
Dit is wat de bovenstaande verdeling vertegenwoordigt:
Stel dat we deze voetballer kunnen overtuigen om 10 penalty's te nemen, hem dan vragen er nog eens 10 te nemen, en dan nog eens, tot 1.000 sets van 10 penalty's. Elke keer berekenen we hoeveel schoten van de 10 hij scoorde, en maken er een histogram van. Dat is wat we hier hebben.
Houd er rekening mee dat de speler nooit 7,7 penalty's kan scoren, of 3,8 trappen, alleen gehele getallen zijn toegestaan op de x-as. Daarom is de binomiale verdeling een discrete kansverdeling, en dit histogram wordt een kansmassafunctie genoemd.
In plaats van je lastig te vallen met verwarrende statistische termen, zoals experiment, gebeurtenis en succes, enz. Laten we de woordenschat van ons voorbeeld hier gebruiken om uit te leggen hoe de binomiale verdeling kan worden gebruikt.
Wanneer je de kans (p) kent dat een speler een penalty scoort. Dan gebruik je de binomiale verdeling om je geloof uit te drukken in hoe waarschijnlijk ze (x) penalty's zullen scoren uit (k) trappen. Zoals je kunt zien, zijn hier twee parameters, de kans (p) en het aantal trappen dat de speler zal nemen (k), en van daaruit kun je de kansmassafunctie plotten in termen van het aantal gescoorde trappen (x).
Zoals vermeld, omdat 10 een zeer klein aantal is, kunnen we er niet zeker van zijn dat de speler 7 van die 10 trappen zal scoren. Je kunt zelfs in de grafiek hierboven zien dat er ongeveer 10% kans is dat ze slechts 5 trappen zullen scoren.
Maar als k een groter getal is, zeg dat de speler 100 penalty's neemt, denk je dan niet dat het zeer onwaarschijnlijk is dat ze er maar 50 van zullen scoren?
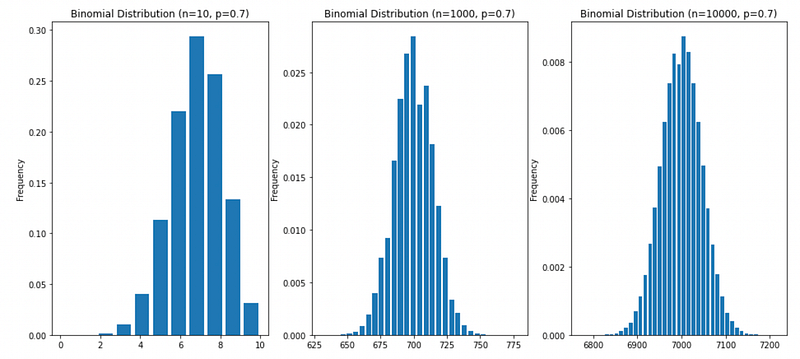
Wat is het punt van statistiek eigenlijk?
Zoals je hierboven kunt zien, als we een speler hebben die 10.000 penalty's in een seizoen zal nemen, en we weten dat hun nauwkeurigheid 70% is, hoeven we ons waarschijnlijk niet druk te maken over al deze verdelingscomplicaties, we kunnen veilig aannemen dat ze 7.000 trappen van die 10.000 trappen zullen scoren, en in het slechtste geval zullen we er 1 of 2% naast zitten (~ 100 / 7.000).
Het belangrijkste punt van statistiek is bij het omgaan met beperkte gegevens, en we kunnen geen definitieve antwoorden geven omdat dingen veel kunnen variëren, zoals in het geval van de 10 trappen, waar we er 40% naast kunnen zitten.
De beta-verdeling
Stel je nu voor dat je een andere vraag stelt. Deze keer weten we de nauwkeurigheid van de speler niet, maar we weten dat hij 10 trappen ging nemen en er 7 van scoorde. Wat is de nauwkeurigheid van de speler?
Zijn nauwkeurigheid is 70%, natuurlijk!
Kom op! Waren we het er niet net over eens dat 10 zo'n klein aantal is, en dat we niet overhaast conclusies moeten trekken?!
Opnieuw hebben we een verdeling nodig om ons geloof in de nauwkeurigheid van de speler weer te geven, en ja, je raadt het al, het is de beta-verdeling die we zoeken. En het neemt twee parameters, a en b, die het aantal successen zijn (a = 7 gescoorde penalty's hier) en mislukkingen (b = 3 gemist).
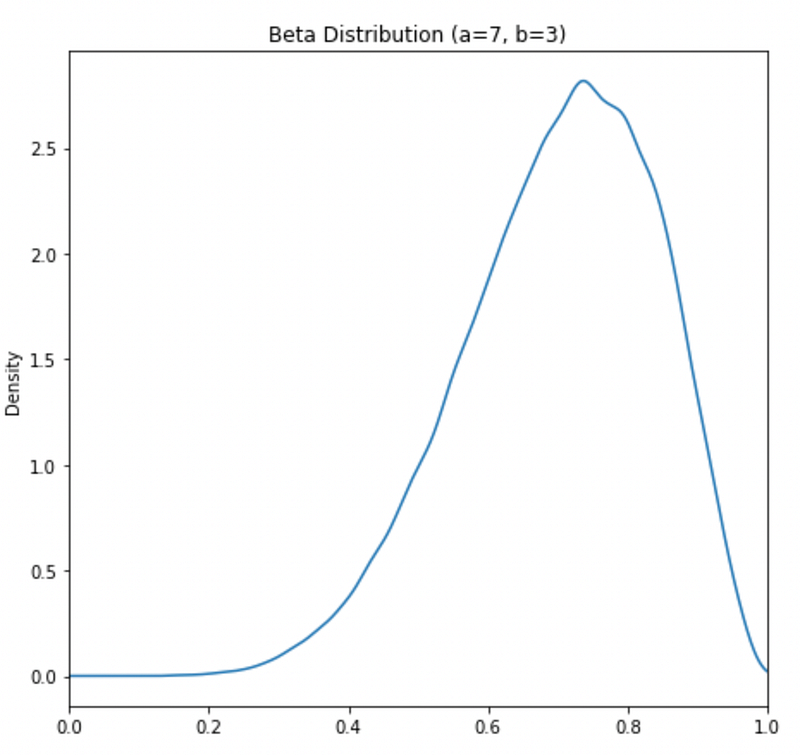
Merk op, kansen kunnen elke waarde aannemen tussen nul en één. Dus, in tegenstelling tot de kansmassafunctie van de binomiale verdeling, kunnen we hier breuken hebben op de x-as, daarom is de beta-verdeling een continue kansverdeling, en deze grafiek wordt een kansdichtheidsfunctie genoemd.
Duidelijk zijn deze twee verdelingen erg nuttig, we kunnen aan tal van dagelijkse problemen denken waarbij we ons geloof moeten uitdrukken in het aantal successen, gegeven dat we het succespercentage kennen, of andersom. Bovendien vergezellen de twee verdelingen elkaar in Bayesiaanse inferentie, aangezien ze toevallig geconjugeerde priors zijn, maar dat is iets voor een toekomstige post.
Tarek Amr, 2 februari 2023